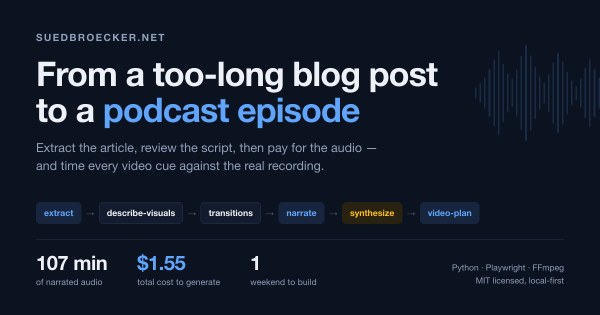
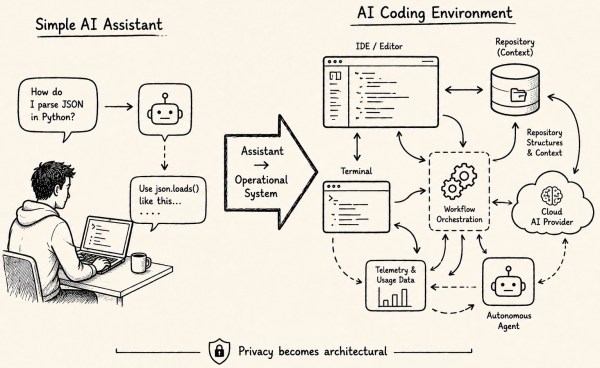
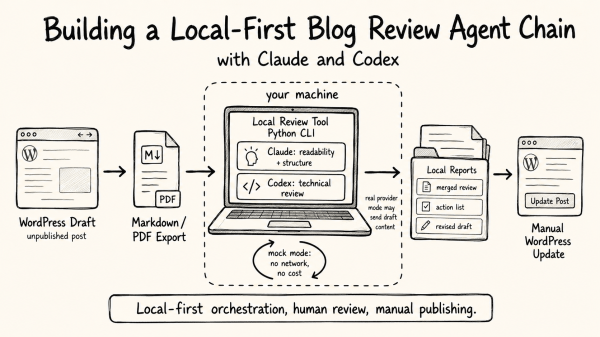
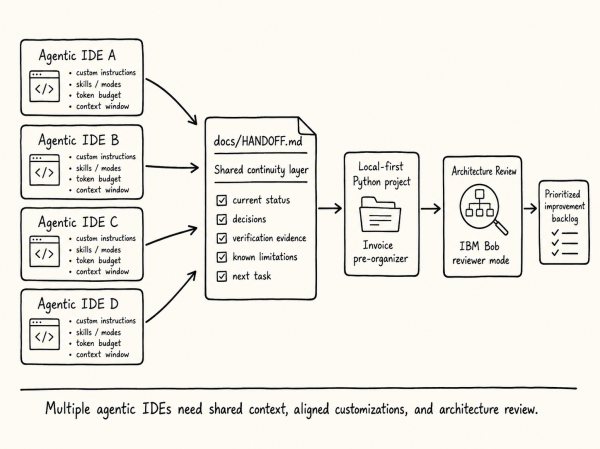
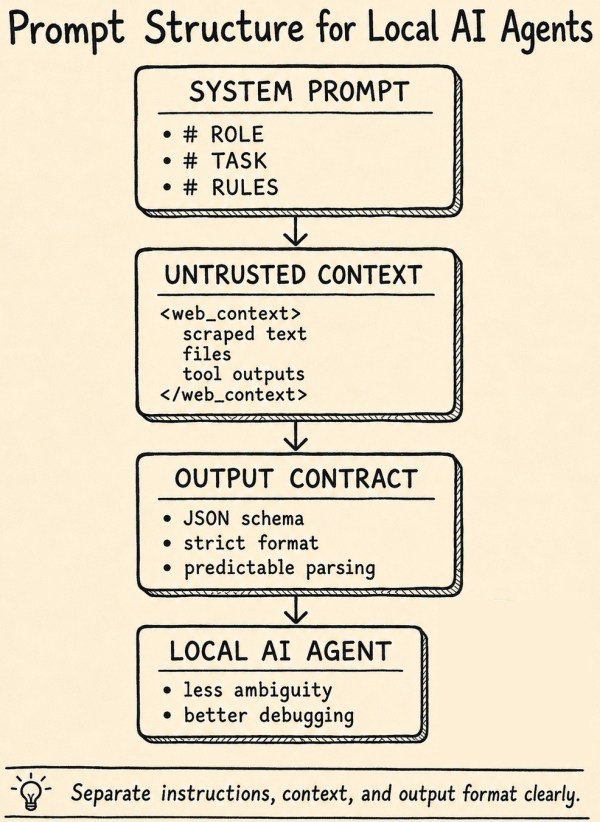
The content details the creation of a tool for converting written posts into narrated audio and video formats using Codex CLI and Claude Code. It covers the tool's functionality, costs, and lessons learned during development, emphasizing accurate audio synchronization and transcript quality. The tool is open-source and freely usable for personal posts.
I Spent a Weekend Building a Podcast Generator for My Own Too-Long Blog Posts