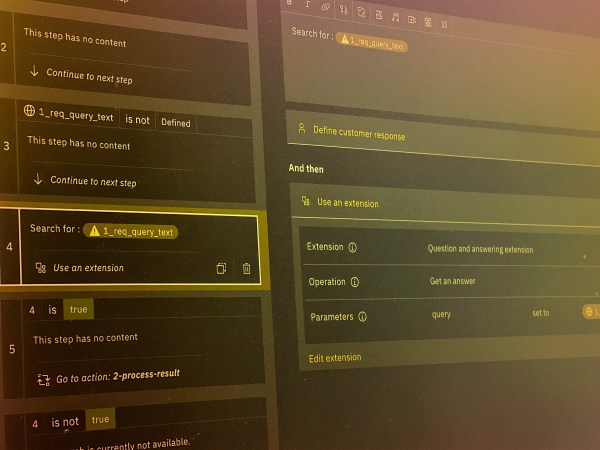
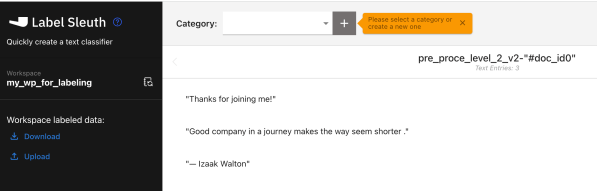
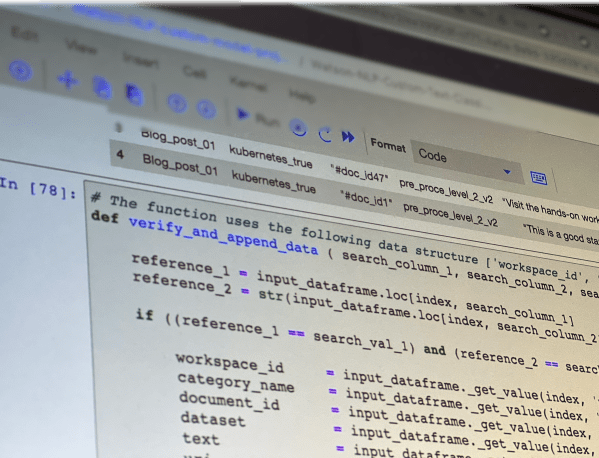
This blog post is about how to set up Bring Your Own Search (BYOS) for the Question Answering Service based on IBM Software in Watson Assistant. The implementation of the Question and answering Service is available on GitHub.
The Setup of Bring Your Own Search (BYOS) for a Question Answering Service in Watson Assistant