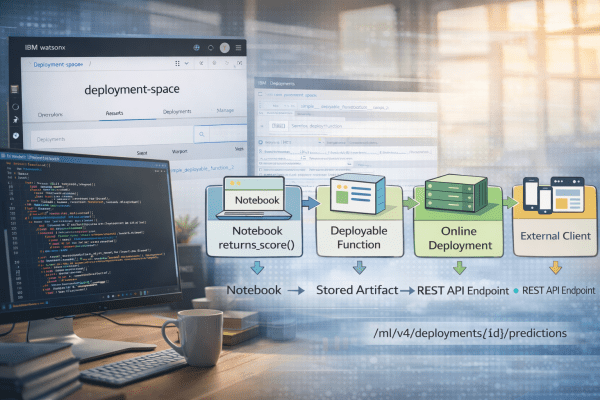
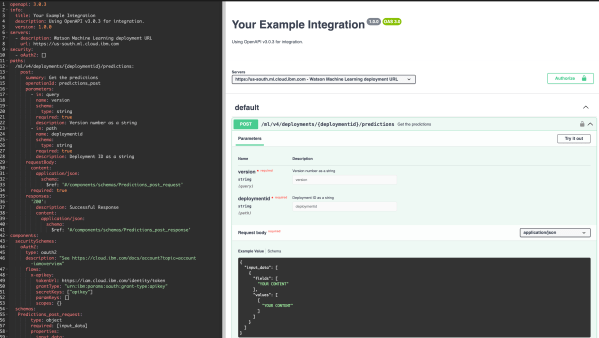
This post outlines the process of creating a deployable function in Jupyter Notebook using watsonx.ai, which is then exposed via a REST API. It emphasizes the separation of development in projects and runtime in deployment spaces, detailing steps from environment setup to function deployment and usage of the API endpoint.
Cheat Sheet: Deploying a Function in watsonx.ai Studio – A Step-by-Step Guide