

This blog post is about IBM Cloud Watson Speech to Text (STT) language model customization. Currently I took a look at the IBM Cloud Watson Assistant service used to build conversational assistants. A conversation leads potentially to speech input of users, which needs to be converted to text to be processed using AI for example the NLU.
With this in mind I took a short look at the Watson STT service.
This is a fast technical overview how to customize an existing language model using cURL inside a bash script. The related source code is available in the GitHub project watson-stt-invocation.
The blog post is organized in following sections:
- Simplified architecture dependencies
- The automation example
- Summary
Simplified architecture dependencies
Let’s have a short look at the simplified architecture dependencies in the image below.

The STT service offers the possibility to customize a base model, with an acoustic model or a language model.
A acoustic model will be used to extend the base model for example with a new accent or jargon for a region. The language model extends the base model with a written text, the text contains unknown words. The text will be provided to the customization model based on a corpora.
A custom acoustic model can be optimized with a custom language model. The written text needs to contain exactly the wording as the audio recording which was used to train the acoustic model. For more details please visit the IBM Cloud documentation: Using the custom acoustic model and custom language model together.
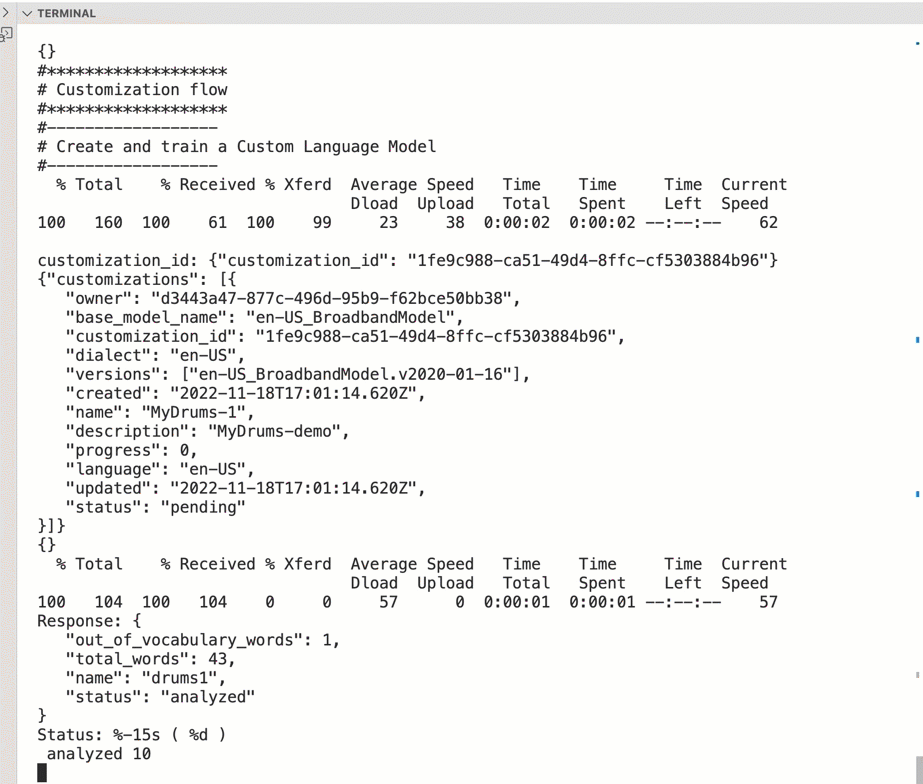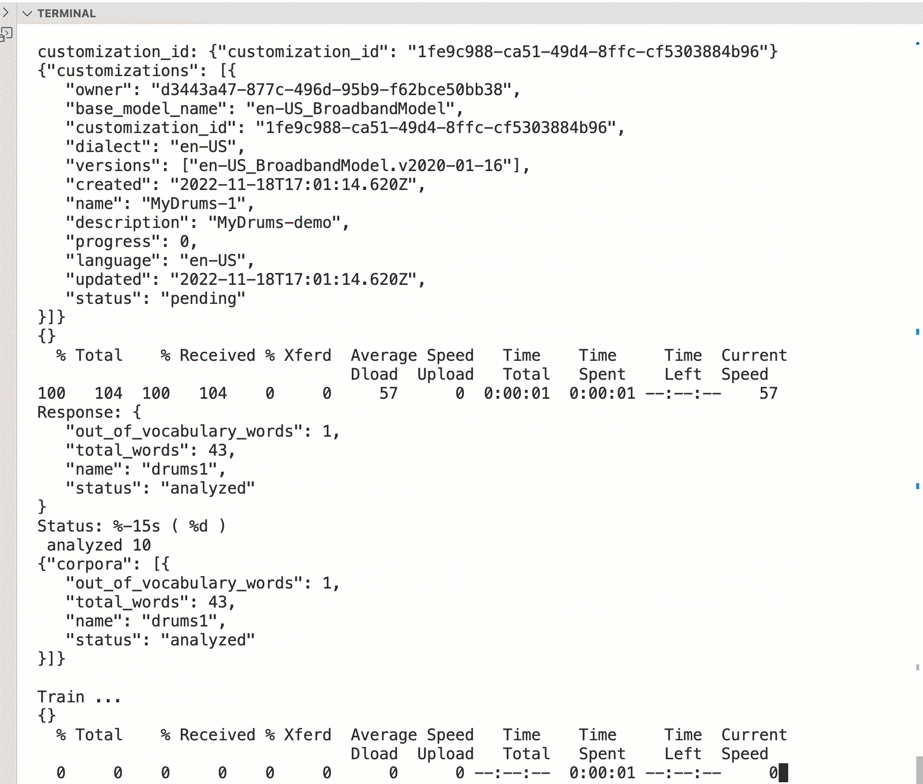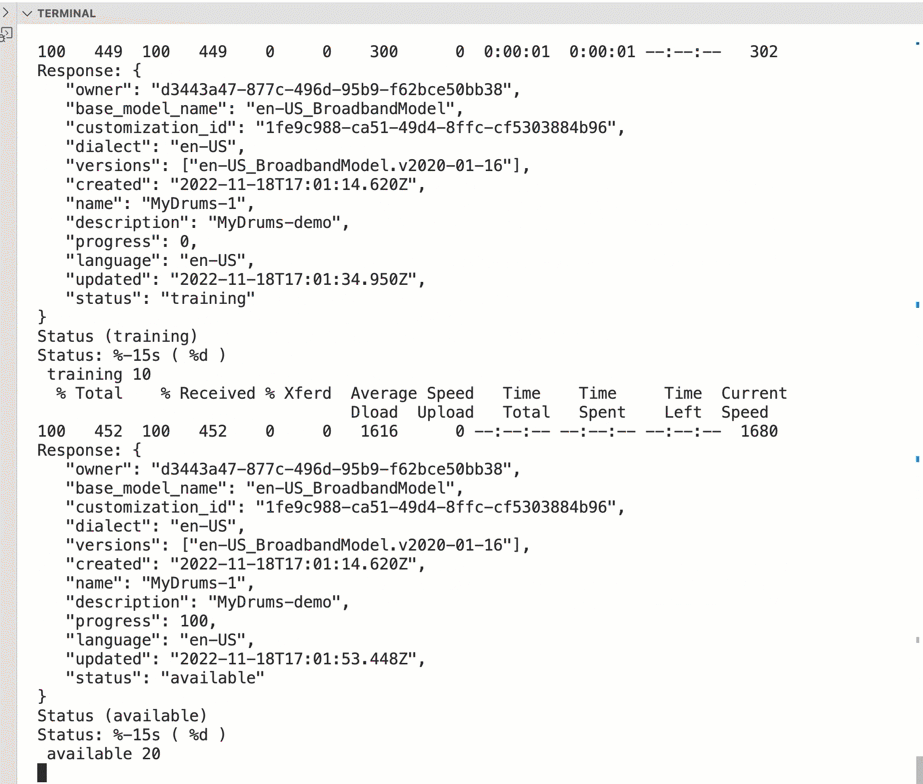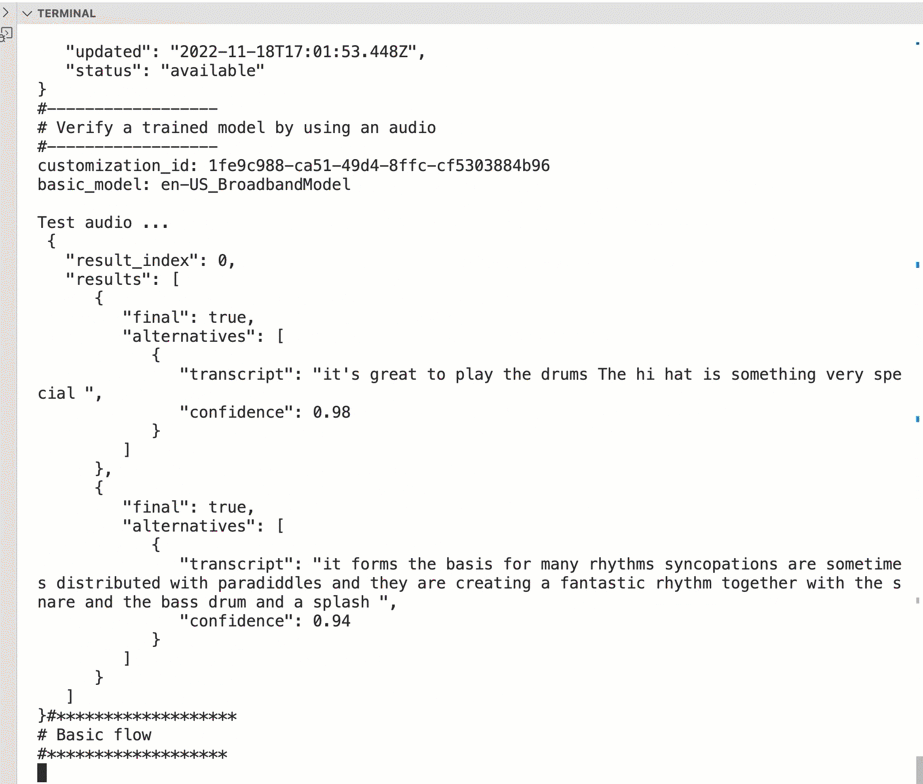
In the example automation of the GitHub project we will customize the EnUSBroadbandModel base model and we call the custom language model drums, as you known I like to play the drums 😉. There I wrote a short text and I recoded a short audio.
It turns out that the word paradiddle was not known by the STT EnUSBroadbandModel, that’s a really special word and mostly only drummers know that word. It is spoken as it is written, so the acoustic model did not have to be improved.
The automation example
The links in the following text are pointing directly to the related source code in the GitHub project watson-stt-invocation.
The bash script automation does implement two flows:
- Basic usage to extract the text from an audio saved in FLAC format using a base language model.
- Customization of an existing language model for the
drumsdomain 😉This are the steps:
The following code is the output of my example automation for my drums custom language model and it worked fine. Surely this was not a complex customization. (confidence is greater than 0.94)
{
"result_index": 0,
"results": [
{
"final": true,
"alternatives": [
{
"transcript": "it's great to play the drums The hi hat is something very special ",
"confidence": 0.98
}
]
},
{
"final": true,
"alternatives": [
{
"transcript": "it forms the basis for many rhythms syncopations are sometimes distributed with paradiddles and they are creating a fantastic rhythm together with the snare and the bass drum and a splash ",
"confidence": 0.94
}
]
}
]
}
The gif below shows a console output of the bash script automation execution.
Summary
The Watson STT service is easy to configure with the curl command and needs no additional interfaces. The API documentation is good and here the list of API calls used in the automation:
Also the getting started in the IBM Cloud documentation is very good.
I hope this was useful for you and let’s see what’s next?
Greetings,
Thomas
#watsonspeechtotext, #bashscript, #stt, #ai, #ibmcloud
