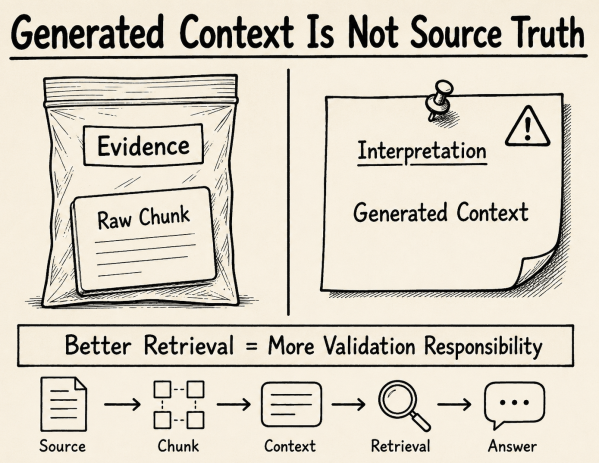
This post reflects on Contextual Retrieval with Milvus in RAG systems. It explains how generated context can improve chunk retrieval, but also changes the retrieval corpus. Once generated context is indexed, validation, traceability, and quality control become architectural responsibilities—not optional implementation details.
Contextual Retrieval with Milvus: Better Retrieval, More Validation Responsibility