The Starting Point: Contextual Retrieval with Milvus
The Basic RAG Pipeline
The Problem: Semantic Isolation of Chunks
Context-Enriched Chunking
Why This Can Help Retrieval
The Design Question: Summary vs. Raw Content
The Risk: Generated Context Inside the Retrieval Corpus
Why Validation Becomes Necessary
A Better Data Structure for Context-Enriched Chunks
How This Fits into Milvus Hybrid Search
Reranking: RRF and Weighted Ranking
What Milvus Provides and What the Application Still Needs
Operational Questions Before Scaling
Summary
References
1. Introduction
Retrieval-Augmented Generation, or RAG, often starts with a very simple mental model.
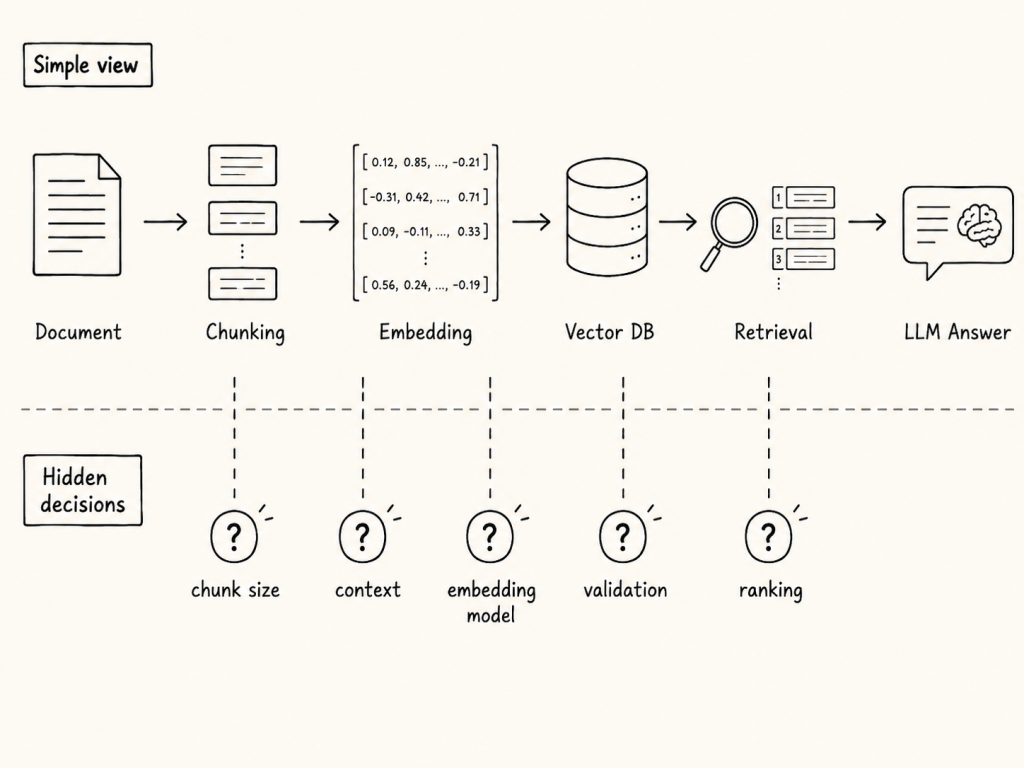
Figure: A simplified RAG pipeline. This model is useful, but it hides many design decisions.
At first, this looks clear.
A document is split into chunks. The chunks are embedded. The embeddings are stored in a vector database. A user asks a question. The system retrieves relevant chunks. The LLM generates an answer based on the retrieved information.
This basic model is useful.
But it also hides many important design decisions.
When we start to use techniques such as Contextual Retrieval, Hybrid Search, multiple vector fields, reranking, and context-enriched chunks, the pipeline becomes more complex.
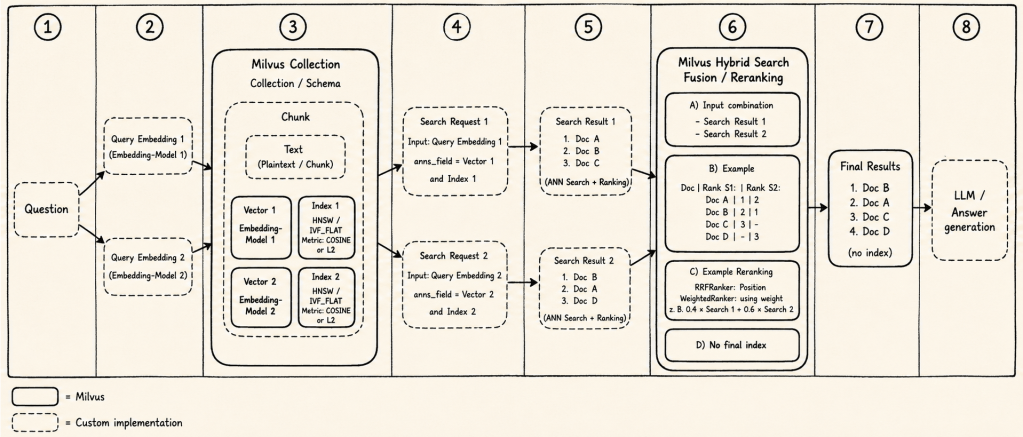
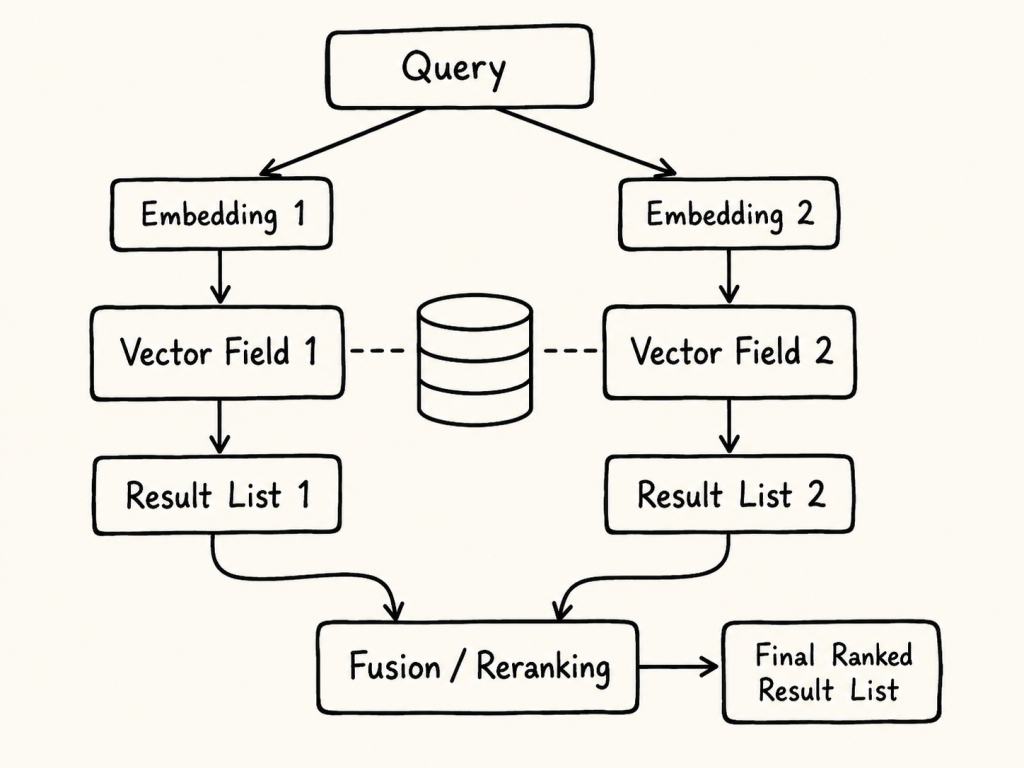
The following diagram shows this complexity in a simplified way. A question can be transformed into different query embeddings, searched against different vector fields and indexes, and then combined through hybrid search, fusion, or reranking before the final context is passed to the LLM.
The important point is that the final answer is not produced by “the vector database” alone. It is produced by a larger retrieval pipeline where Milvus provides important search infrastructure, while the application still owns embedding strategy, result combination, validation, and answer grounding.
Figure: A simplified view of a Milvus Hybrid Search pipeline with multiple embeddings, vector fields, indexes, result lists, reranking, and final LLM answer generation.
The starting point for this post was the Milvus documentation “Contextual Retrieval with Milvus”. The Milvus article describes how contextual information can be added to chunks before embedding and indexing. The goal is to reduce the semantic isolation of chunks and improve retrieval quality in RAG systems.
That makes sense.
A chunk without context can be difficult to retrieve correctly. It may contain a reference, a continuation, or a partial explanation that only makes sense when the surrounding document is known.
Contextual Retrieval tries to improve this by adding a short context to the chunk. But this raises another important question:
What happens when generated context becomes part of the retrieval corpus?
The question matters because retrieval quality problems are often not visible as system errors. The system may still return an answer. But the answer may be based on generated enrichment that was never validated.
This post looks at that question. Not only from the perspective of retrieval quality. But also from the perspective of architecture, validation, traceability, and risk.
Note: This post is not a step-by-step reproduction of the Milvus tutorial. I use the Milvus article as a starting point, but I look at the topic from another angle: what happens when generated context becomes part of the retrieval corpus?
2. The Starting Point: Contextual Retrieval with Milvus
The Milvus documentation explains Contextual Retrieval as an advanced retrieval approach for RAG systems.
The core problem is that classical chunking can isolate a chunk from its surrounding document context.
A chunk may contain:
a reference to something explained earlier
a continuation of an argument
a partial explanation
a domain-specific term
a table description
a sentence that only makes sense in the larger document context
When this chunk is embedded alone, some of its meaning can be lost. The retriever may not find the right chunk because the chunk itself does not contain enough semantic information.
Contextual Retrieval tries to reduce this problem by adding additional context to the chunk before embedding and indexing. The Milvus article mainly focuses on how contextual information can improve retrieval quality. That is useful.
But in this post, I want to look at the same idea from another angle:
What changes architecturally when generated context becomes part of the retrieval corpus?
What are the architectural consequences when generated context becomes part of the retrieval corpus?
This difference is important. This is the moment where the data object changes.
A context-enriched chunk is no longer only raw source content.
3. The Basic RAG Pipeline
A basic RAG pipeline often looks simple:
Figure: A simple RAG pipeline is easy to explain, but every step hides architectural decisions.
This simple pipeline is easy to explain.
But it does not answer several important questions:
How are chunks created?
How large should a chunk be?
Should neighboring context be included?
Should the chunk contain only original text?
Should generated summaries be added?
Which embedding model is used?
Are there multiple vector fields?
How are search results combined?
How is the final context selected for the LLM?
These questions become important when the system moves from a demo to a more serious implementation.
4. The Problem: Semantic Isolation of Chunks
Chunking is necessary because documents are often too large to embed or send to an LLM as one complete unit.
But chunking also creates a problem:
A chunk can lose its surrounding meaning. A chunk may still be technically correct, but semantically incomplete.
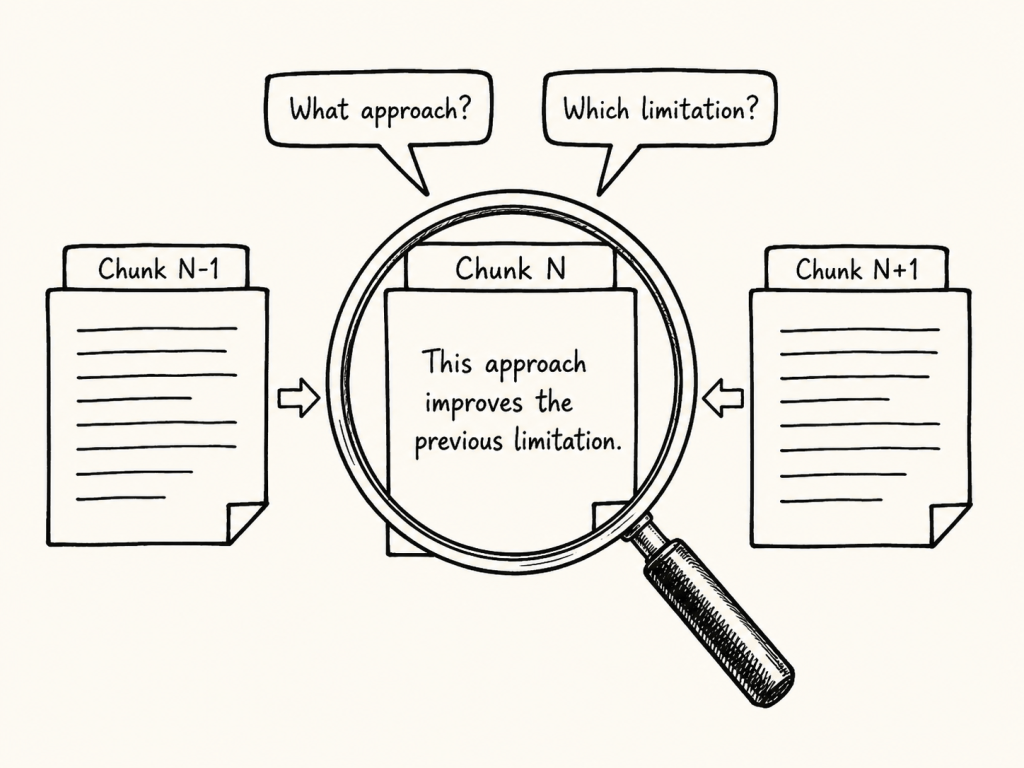
For example, a chunk may start with:
This approach improves the previous limitation.
Figure: A chunk may be technically correct, but still semantically incomplete when its surrounding context is missing.
But what is “this approach”? What was the previous limitation?
The answer may be in the previous chunk.
Or a chunk may contain a table, while the explanation of the table appears in the next chunk. Or a chunk may begin with a reference such as “this”, “that result”, or “they”, without enough local context to explain what it refers to.
This is the core issue behind Contextual Retrieval:
The chunk is available, but the local meaning is incomplete.
Contextual Retrieval tries to reduce this problem by enriching the chunk with additional context before it is embedded.
5. Context-Enriched Chunking
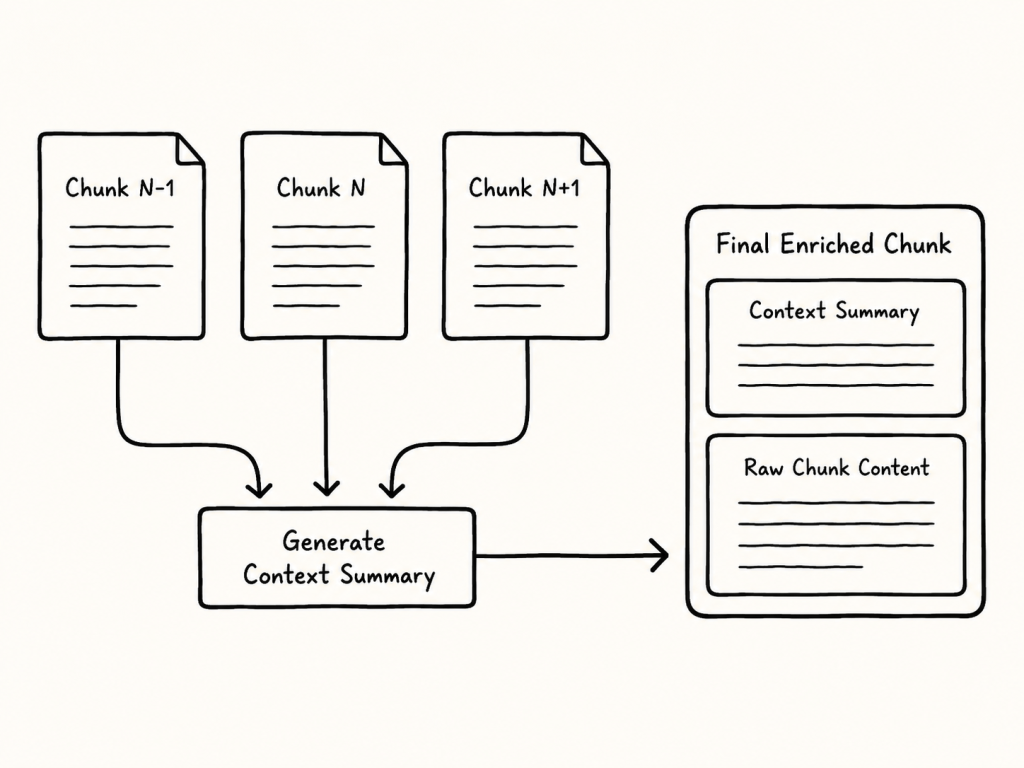
One possible approach is to create a local context window around a target chunk.
For example, the system can use:
Chunk N-1
Chunk N
Chunk N+1
The goal is not to replace the raw chunk.
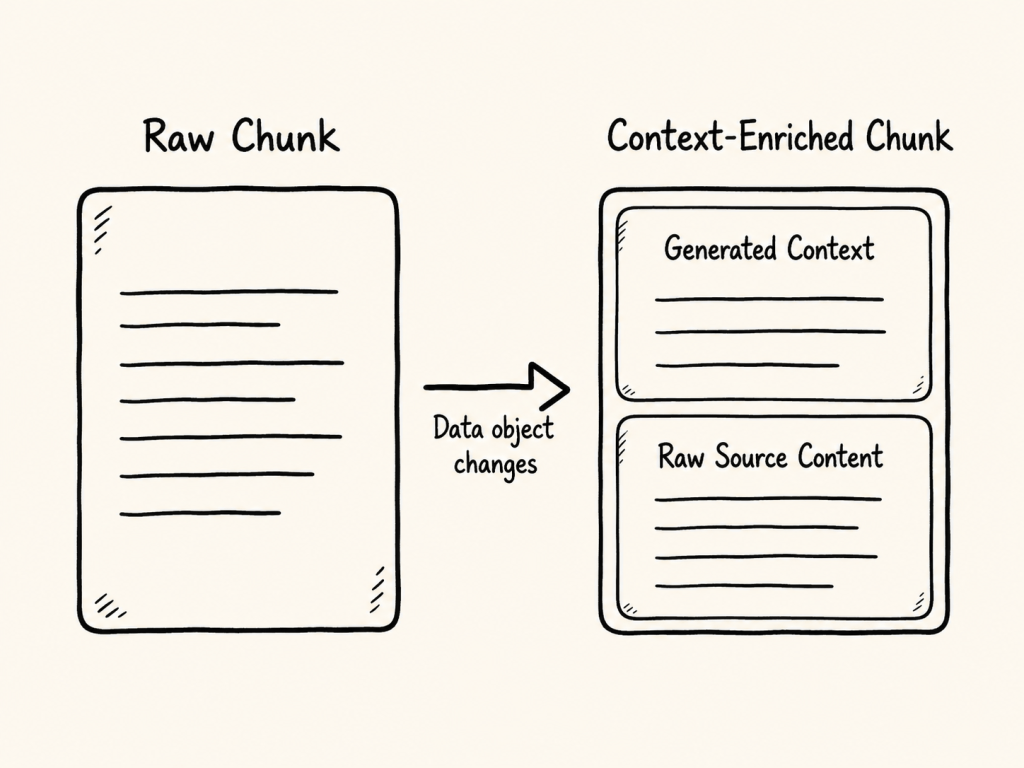
Figure: A local context window can use neighboring chunks to generate a short context summary for the current chunk.
The goal is to generate a short context summary that explains the local meaning of Chunk N.
The final enriched chunk then contains two clearly separated parts:
Context Summary
Raw Chunk Content
The Context Summary explains the local meaning of the current chunk.
The Raw Chunk Content preserves the original information from the source document.
This distinction is important.
The context summary is generated. The raw chunk content is source material.
That means the final enriched chunk contains both original information and generated interpretation.
Final enriched chunk contains both original information and generated interpretation.
6. Why This Can Help Retrieval
A raw chunk can be too isolated.
It may not contain enough information for a vector search to identify it as relevant. Embedding models do not only work with exact words. They try to represent the meaning of the text. If the chunk contains too little meaning by itself, the embedding can also become too weak or too ambiguous.
Instead of embedding only this:
The method reduces this issue by adding context before indexing.
The system may embed something closer to this:
This chunk explains how Contextual Retrieval reduces semantic isolation in RAG systems by adding generated context before embedding and indexing.
Now the chunk contains terms that are closer to what a user may actually ask for, such as “semantic isolation”, “RAG systems”, or “context before embedding”.
This can make the chunk easier to retrieve.
Especially when the user asks a question that refers to the broader meaning of the section rather than to exact words inside the original chunk.
So the benefit is clear:
More context can improve retrievability. But there is also a cost.
7. The Design Question: Summary vs. Raw Content
A key design question is:
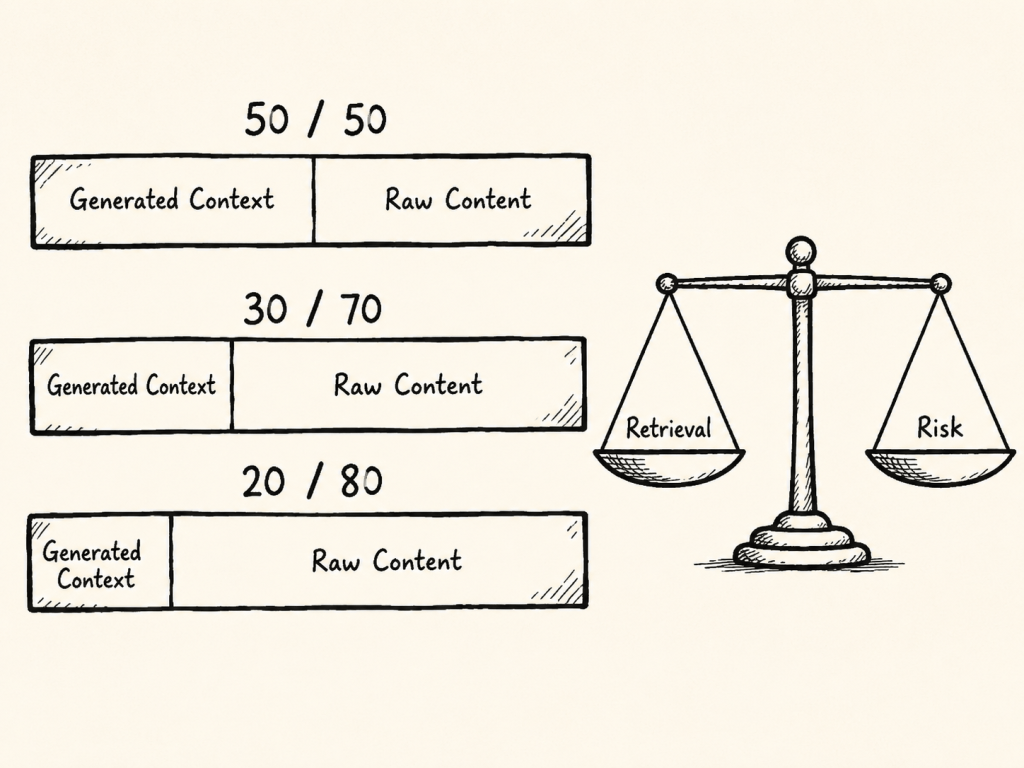
How much of the final chunk should be generated context, and how much should be raw source content?
This is not a formatting question. It is a quality and risk decision.
Possible ratios could be:
Option
Generated Context
Raw Source Content
Possible Effect
High context ratio
50%
50%
More semantic signal, more generated content
Balanced context ratio
30%
70%
Moderate enrichment, stronger source grounding
Low context ratio
20%
80%
Less generated risk, possibly weaker retrieval improvement
This decision affects:
Figure: The ratio between generated context and raw source content is a retrieval-quality and validation-risk decision.
retrieval quality
embedding behavior
token usage
storage size
traceability
hallucination risk
and answer quality
A larger context summary may improve semantic retrieval because the chunk contains more explanatory signal. But it also increases the amount of generated text inside the retrieval corpus. A smaller context summary may reduce hallucination and distortion risk. But it may not provide enough additional context to improve retrieval.
So the question is not only technical. It is also a quality decision.
8. The Risk: Generated Context Inside the Retrieval Corpus
Generated context is useful. But it introduces a new risk.
The dangerous part is that this generated interpretation may later look like normal indexed knowledge.
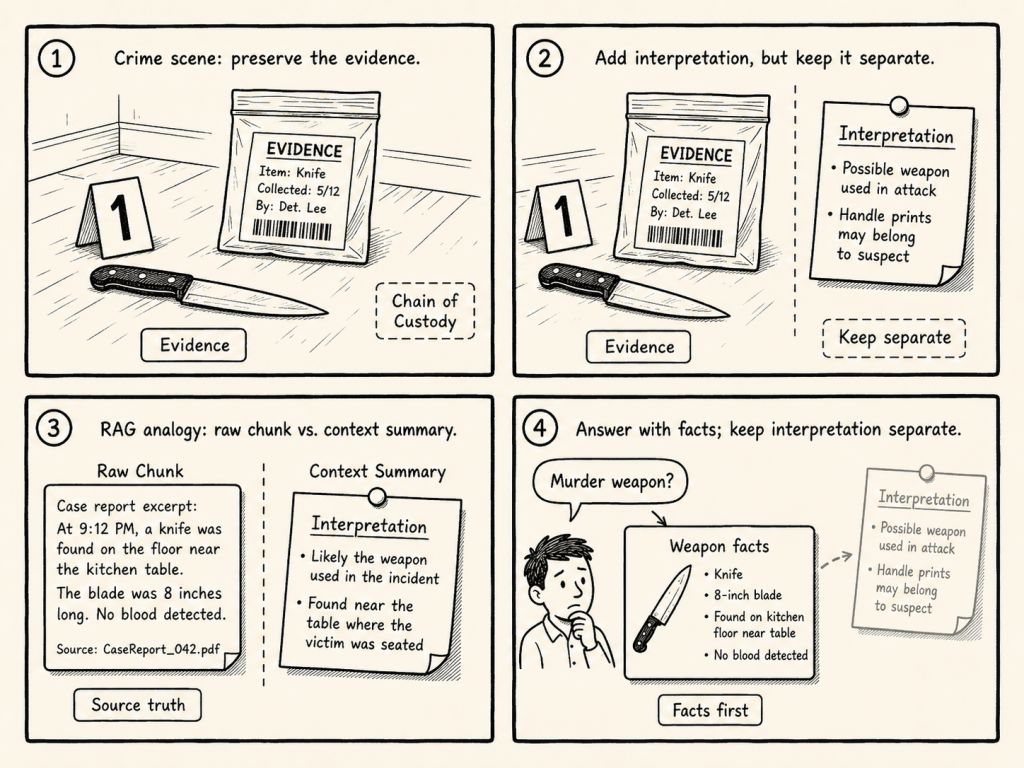
A simple analogy is a crime scene.
At a crime scene, the original evidence must not be changed. The important principle is the chain of custody: what was found, where it was found, who collected it, and how it was preserved.
Additional notes, interpretations, and hypotheses can be useful.
But they must not become indistinguishable from the original evidence.
This is similar to how I think about chunks in a RAG system.
> The raw chunk is the evidence. > The generated context summary is an interpretation.
It may help to understand the evidence, but it is not the same as the original source content. If generated interpretation is merged into the chunk without clear separation, the system may later treat interpretation as if it were source truth.
For example, if someone asks about the murder weapon, they should receive facts that are grounded in the original evidence, not premature conclusions that were added later as interpretation.
If the summary is generated by an LLM, the retrieval corpus no longer contains only original document content. It also contains generated interpretation. The dangerous part is that this generated interpretation may later look like normal indexed knowledge.
The generated summary may:
hallucinate facts
distort the original meaning
overgeneralize
introduce terms that were not in the source
remove important nuance
make a chunk look more relevant than it really is
This can become especially difficult at scale.
For example:
50,000 chunks × one generated context summary per chunk = 50,000 generated artifacts
Figure: At scale, generated context summaries become a quality-control problem.
Manual validation becomes unrealistic. At this point, context generation is no longer only a preprocessing step.
It becomes a quality-control problem.
And if this quality-control problem is ignored, generated context can silently become part of the system’s trusted retrieval memory. That is the part I find especially important.
Contextual Retrieval may improve search.
But it also increases the responsibility to control what is added to the retrieval pipeline.
9. Why Validation Becomes Necessary
If generated summaries are added to chunks, validation should become part of the architecture.
The system should not simply generate 50,000 summaries and assume that all of them are correct.
In the crime-scene analogy, validation is the process that checks whether the evidence and the interpretation are still clearly separated.
For RAG, this means checking whether the generated context summary is still grounded in the raw chunk and its surrounding source context.
Possible validation approaches include:
– sampling-based review, – automated consistency checks, – source-grounded verification, – Model-as-a-Judge, – rules for summary length and structure, – comparison against the original chunks, – validation status per chunk, – audit metadata.
A generated context summary should be checked for at least four things:
– Does it stay grounded in the original chunk and neighboring chunks? – Does it introduce new facts? – Does it preserve important limitations or uncertainty? – Does it make the chunk look more relevant than the source content justifies?
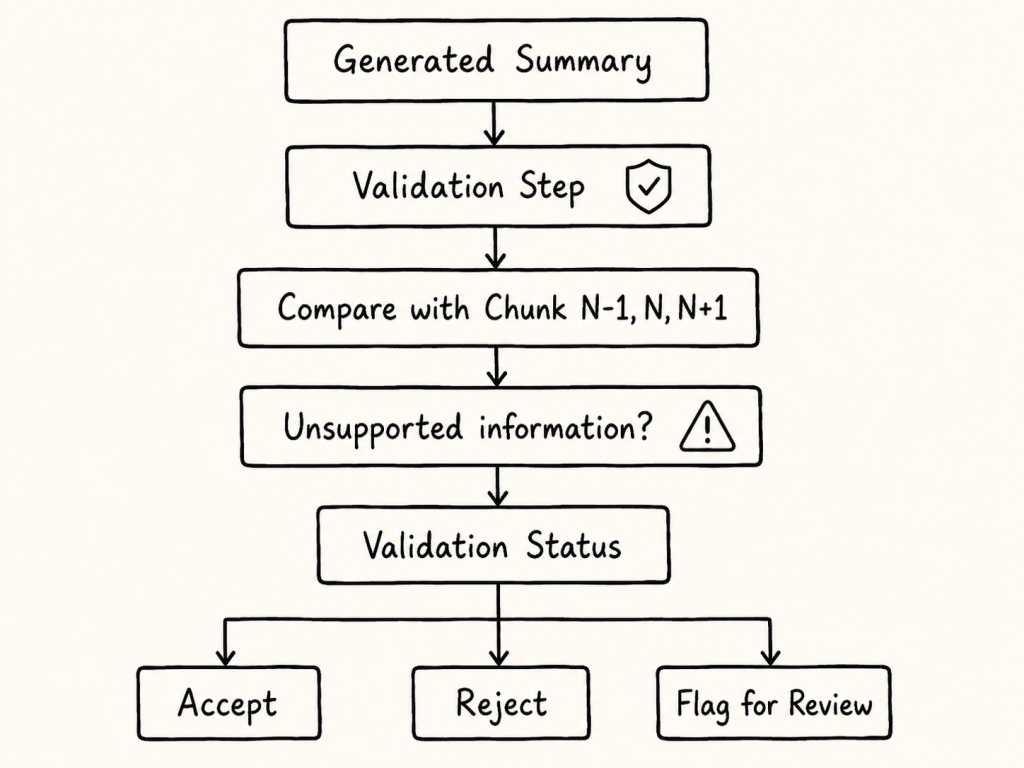
A simple validation flow could look like this:
1. Generate a context summary. 2. Compare it against Chunk N-1, Chunk N, and Chunk N+1. 3. Check whether the summary introduces unsupported information. 4. Assign a validation status. 5. Store the result together with the chunk metadata.
The validation result should not only exist in logs.
It should become part of the chunk metadata, for example:
This does not eliminate all risk. But it makes the risk visible. And that is already important. Because without validation, generated context can quietly become part of the retrieval corpus.
Later, the LLM may use this generated context as if it were source truth.
10. A Better Data Structure for Context-Enriched Chunks
If generated context becomes part of the retrieval process, then the chunk structure should reflect that clearly. A context-enriched chunk should not be stored as one merged text block without distinction.
Instead, the structure should separate:
original source content
generated context
embedding input
validation status
and traceability metadata
This separation matters because the system should always be able to answer three questions:
What is original source content?
What is generated interpretation?
What was actually used for embedding and retrieval?
A possible structure could look like this:
{
"chunk_id": "doc-001-chunk-010",
"doc_id": "doc-001",
"previous_chunk_id": "doc-001-chunk-009",
"next_chunk_id": "doc-001-chunk-011",
"raw_chunk_content": "… original source text …",
"context_summary": "… generated local context …",
"embedding_input": "… context summary + raw chunk content …",
The separated chunk structure from the previous section also helps when thinking about Milvus Hybrid Search.
If raw content, generated context, embedding input, and metadata are clearly separated, the application can decide which representation should be embedded, searched, or used for the final answer. This becomes especially relevant when a Milvus collection contains multiple vector fields.
For example, one collection could contain different vector fields for different retrieval perspectives:
one vector field for the raw chunk content,
one vector field for the context-enriched embedding input,
optionally one vector field for another representation, such as a title, section summary, or domain-specific embedding.
Each vector field can have its own index.
Vector Field 1 → Index 1 Vector Field 2 → Index 2
Example:
A user question can also be embedded in different ways.
Example:
Query Embedding 1 → Search Request 1 → Result List 1
Query Embedding 2 → Search Request 2 → Result List 2
Each search request points to a specific vector field. Each search request produces its own ranked result list.
Example:
Result List 1: 1. Doc A2. Doc B 3. Doc C
Result List 2: 1. Doc B2. Doc A 3. Doc D
These result lists are then combined by fusion or reranking.
The important point is:
There is no final index. There is a final ranked result list.
The final result is created through fusion or reranking.
It is not created by writing results into another index.
Milvus can store and search these vector fields, but the application design defines what each vector field actually means.
Figure: Milvus Hybrid Search can combine multiple search paths into one final ranked result list.
That final ranked list is what the application can use to construct the context for the LLM.
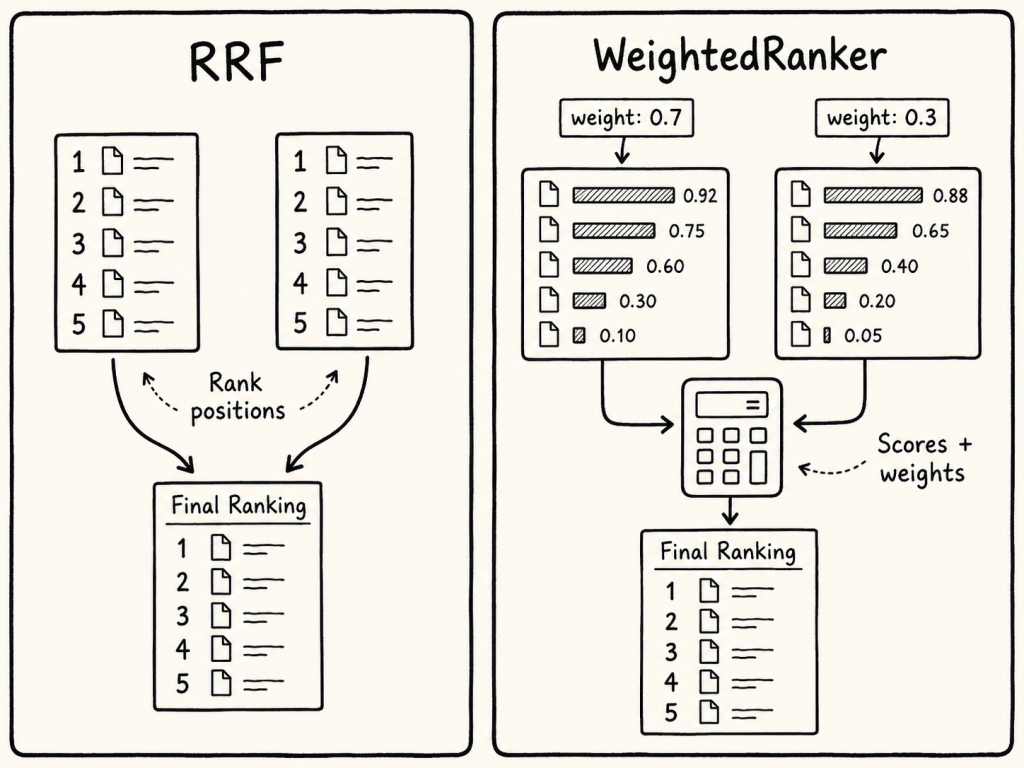
12. Reranking: RRF and Weighted Ranking
After Milvus Hybrid Search returns multiple result lists, the system needs a way to combine them into one final ranked list.
Two common approaches are:
RRFRanker
WeightedRanker
Figure: RRF focuses on rank positions, while WeightedRanker combines scores using explicit weights.
RRF means Reciprocal Rank Fusion. It uses rank positions instead of relying only on raw scores. This is useful when scores from different search paths are difficult to compare.
Example:
Result List 1: 1. Doc A 2. Doc B 3. Doc C
Result List 2: 1. Doc B 2. Doc A 3. Doc D
RRF rewards documents that appear high in multiple result lists. In this example, Doc A and Doc B are both strong candidates because they appear near the top in both lists.
Weighted ranking is useful when one search path should count more than another.
Example:
Final Score = 0.4 × Score from Search 1 + 0.6 × Score from Search 2
This may be useful when one embedding model is more domain-specific than the other.
For example:
Search path 1 uses a general embedding model.
Search path 2 uses a domain-specific embedding model.
The domain-specific search path gets a higher weight.
Both approaches can make sense.
The right choice depends on the retrieval goal and the quality of the individual search paths.
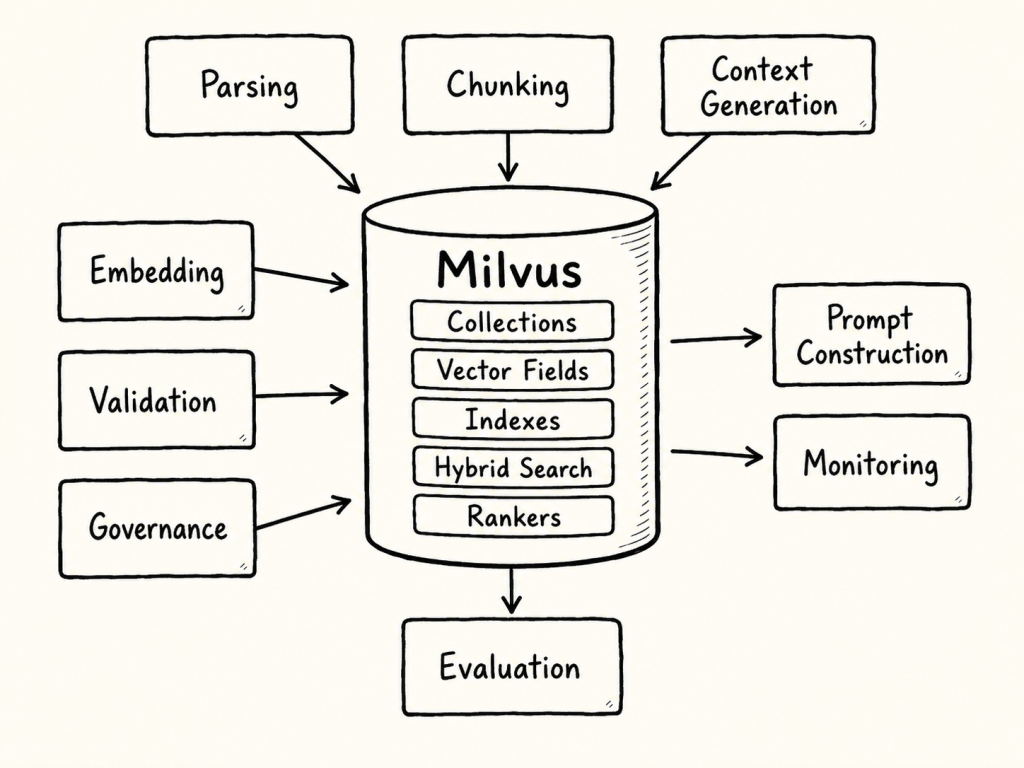
13. What Milvus Provides and What the Application Still Needs
Milvus can provide important retrieval infrastructure. But Milvus is not the whole RAG system.
A useful distinction is this:
Area
Milvus can provide
The application still needs to handle
Data organization
Collections, schemas, vector fields
Document parsing, chunking, metadata preparation
Vector search
Indexes, ANN search, search requests
Embedding generation and embedding strategy
Hybrid retrieval
Multiple vector fields, hybrid search
Deciding what each vector field means
Ranking
Rankers and final ranked result lists
Choosing ranking strategy and evaluating result quality
Retrieval output
Candidate chunks and scores
Prompt construction and answer generation
Operations
Retrieval infrastructure
Validation, monitoring, governance, traceability
This distinction is important. Contextual Retrieval is not only a Milvus configuration. It is an architectural decision across the whole RAG pipeline.
Figure: Milvus provides retrieval infrastructure, but the application still owns the surrounding RAG pipeline responsibilities.
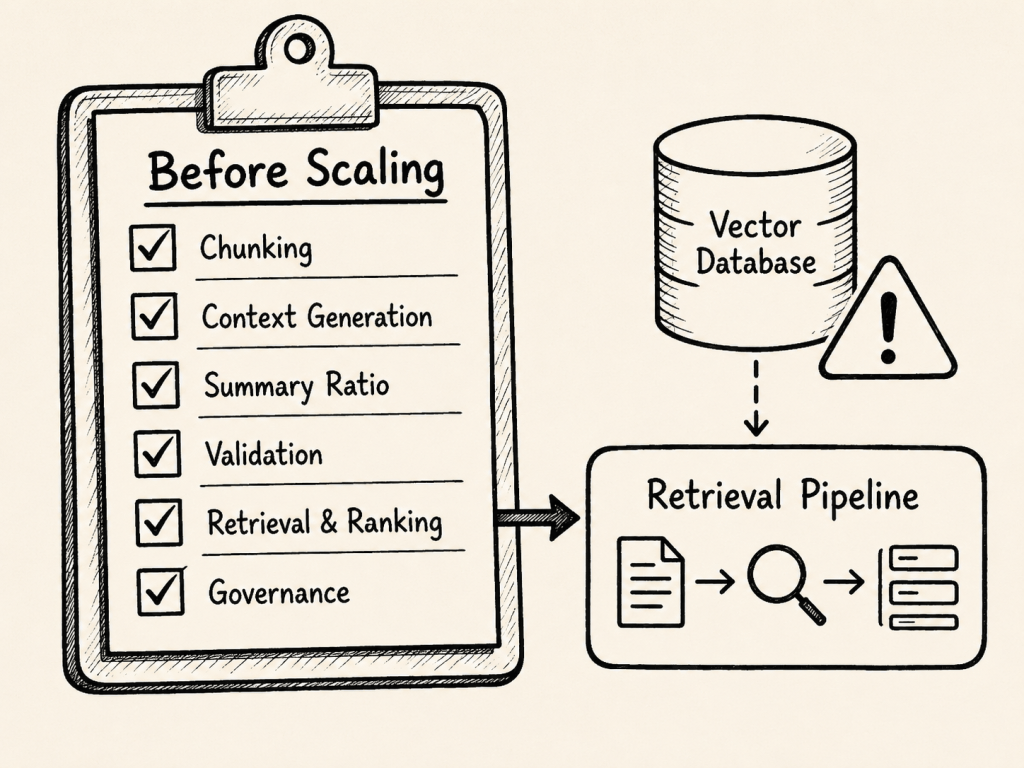
14. Operational Questions Before Scaling
Before using Contextual Retrieval at scale, I would not start with the question:
Can this improve retrieval?
I would start with a different question:
Can we still understand, validate, and trace what the system is doing?
The following questions help make that visible:
Area
Operational question
Chunking and context
How are chunks created, and how many neighboring chunks are used for context?
Context generation
Which model creates the context summary, and can it introduce new facts?
Summary ratio
How much generated context is allowed compared to raw source content?
Validation
How are generated summaries checked, scored, and flagged for review?
Retrieval and ranking
Which vector fields, indexes, and rankers are used, and how is retrieval quality evaluated?
Governance and traceability
Can every answer be traced back to raw source content and validated metadata?
These questions are not optional details. They define whether the system is understandable and trustworthy when it scales.
The core point is simple:
Scaling Contextual Retrieval is not only about indexing more chunks. It is about keeping control over what enters the retrieval pipeline and whether the system remains understandable and trustworthy.
15. Summary
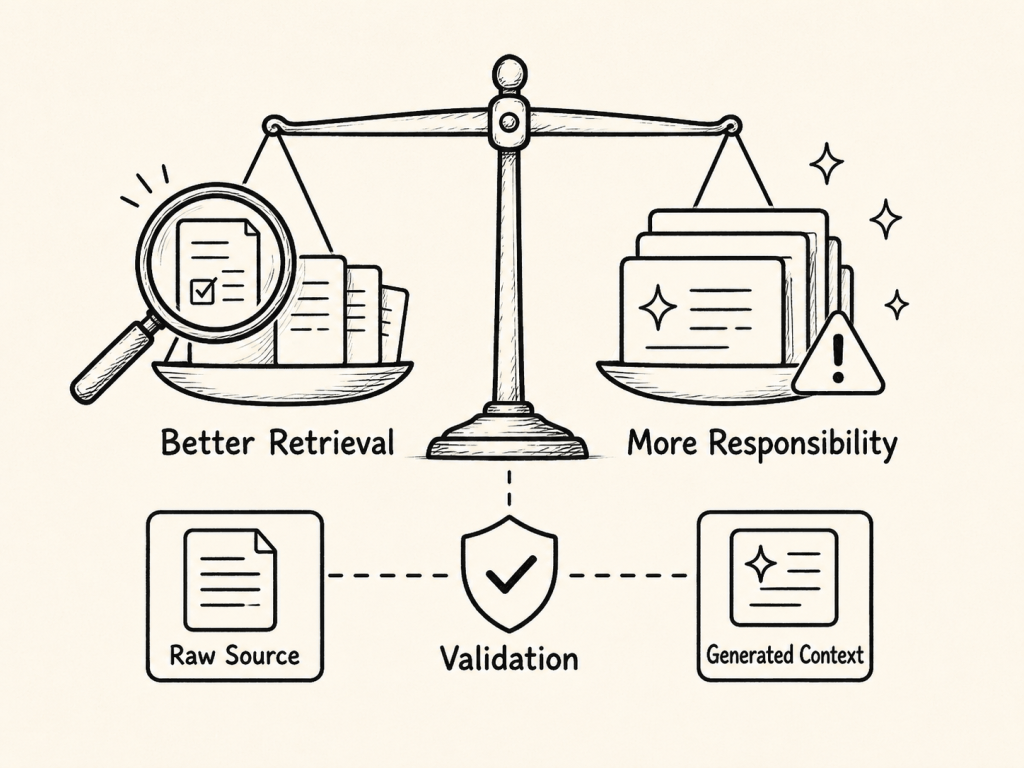
Contextual Retrieval can improve retrieval quality. Milvus Hybrid Search can help combine multiple retrieval perspectives. But the combination of generated context, multiple vector fields, and reranking also increases architectural complexity.
The key trade-off is:
Better retrieval context vs. more generated content inside the retrieval corpus
This trade-off needs to be visible.
Otherwise, it is easy to think that Contextual Retrieval is only a retrieval optimization.
But it is more than that.
It changes how chunks are prepared, stored, embedded, retrieved, ranked, and validated. Once generated context becomes part of the indexed content, the system needs stronger quality control.
The main lesson is simple:
Better retrieval comes with more responsibility.
The more generated context enters the retrieval pipeline, the more important it becomes to separate raw source content from generated enrichment.
And the more important it becomes to validate that enrichment at scale.
So Contextual Retrieval with Milvus is powerful. But it should not be treated only as a database or indexing feature. It is an architectural decision across the whole RAG pipeline.
16. References
This post is my personal interpretation and architectural reflection based on the Milvus documentation and my own reasoning about RAG system design. It is not an official Milvus implementation guide.
Note: This post reflects my own ideas and experience; AI was used only as a writing and thinking aid to help structure and clarify the arguments, not to define them.




Leave a comment