Today, many AI systems are built from impressive technical components: MCP servers, vector databases, graph databases, agents, tools, and large context windows.
In practice, however, I increasingly notice that the biggest mismatch is often not in the orchestration. It is in the data. If the available data is incomplete, outdated, badly extracted, inconsistent, untrusted, or simply not aligned with the real user expectation, the AI system will fail — even when the architecture looks modern and technically strong.
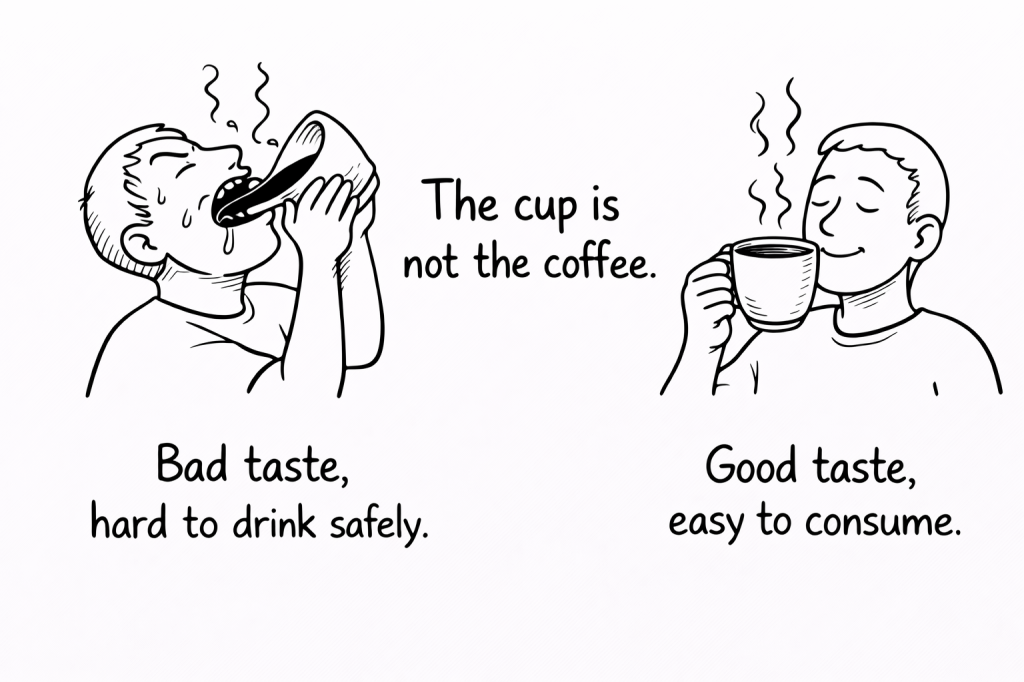
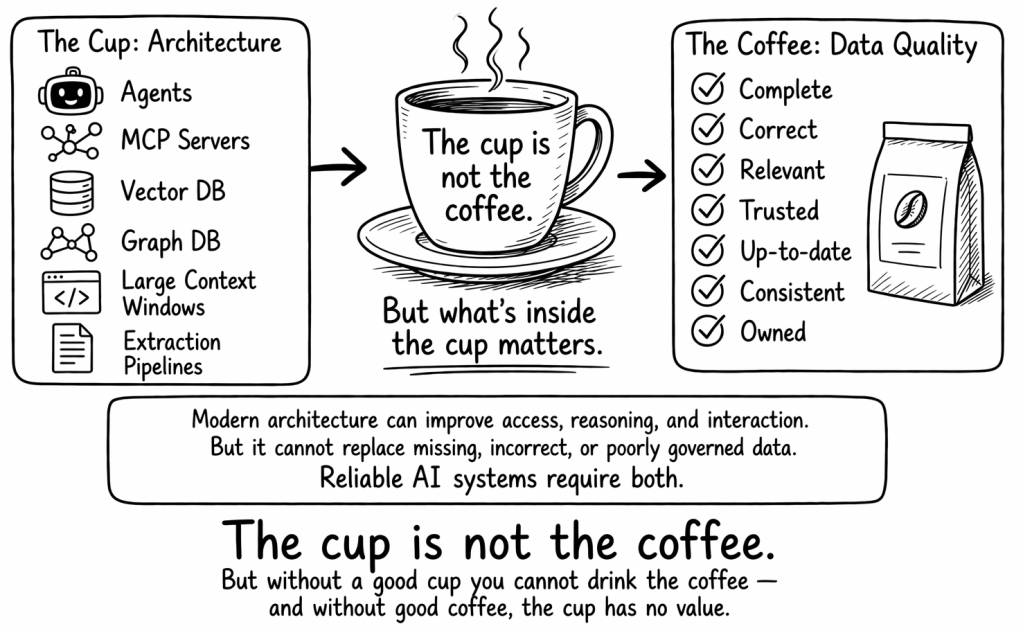
That is why I like this simple picture:
Because in the end:
The cup is not the coffee.
But without a good cup you cannot drink the coffee — and without good coffee, the cup has no value.
Reliable AI systems require both. And in AI systems, the coffee is the data.
A beautiful cup does not fix bad coffee. In the same way, a modern AI architecture does not fix weak data.
Table of contents
Why I think this matters now
RAG versus large context is not the real question
Data quality in the AI era
Relevant dimensions of data quality
Relevance
Correctness
Completeness
Consistency
Timeliness
Traceability
Ownership
Integrity
Usability for AI
What is golden data?
Tools like Docling help a lot — but they do not solve the whole problem
A simple example from beginning to end
The available data
Step 1 — Extraction
Pros
Cons
Step 2 — Chunking and indexing
Pros
Cons
Step 3 — Agent behavior
Pros
Cons
Step 4 — The result
What this example shows
Relevance
Golden data
Mismatch between data and expectation
Ownership
Compromised or degraded data
Who collects the data
AI context
Why the same data performs differently across AI architectures
In a long context prompt
In RAG
In an agent workflow
In an agent-based architecture, multiple tools and steps may be involved.
Summary
References
1. Why I think this matters now
In recent years, I have seen more and more AI systems built from strong technical components.
The components are often not the problem.
The bigger problem is usually somewhere else:
The available data does not match the real task. For example, the system has general policy information, but the user asks about a region-specific case.
The important exception is missing. For example, the main rule is indexed, but the promotional exclusion is not.
The extracted data lost structure. For example, a table with conditions, notes, and exceptions is reduced to flat text.
The source is not authoritative. For example, the system retrieves a copied wiki page instead of the approved source of truth.
The content is outdated. For example, an older process description is still available and sounds valid, although the process has already changed.
Nobody really knows who owns the data. For example, several teams contribute information, but no team is clearly responsible for maintaining it.
The user expects certainty, but the system only has partial information. For example, the answer sounds reliable, but the underlying knowledge base is incomplete.
This becomes even more important when AI is used in areas where the user cannot easily validate the result.
That is a key point for me.
If a user asks something simple, they may notice when the answer is wrong. But if the AI supports analysis, decisions, recommendations, support tasks, or process guidance, the user often cannot fully verify the outcome.
In these situations, data quality is not just a technical detail. It becomes a trust topic.
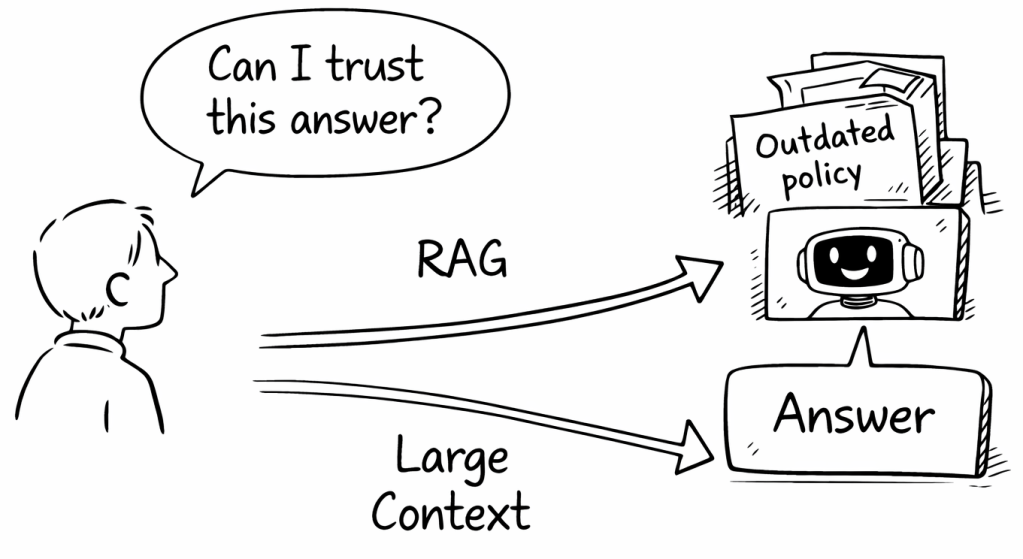
2. RAG versus large context is not the real question
Today, there is a lot of discussion about RAG versus large context windows.
That is a useful technical discussion. But I think it can miss the deeper issue. RAG still depends on good data. Large context still depends on good data. Agents still depend on good data. Graph-based retrieval still depends on good data. Tools exposed through MCP still depend on good data.
It does not matter whether the data is retrieved, injected into context, traversed as a graph, or accessed through a tool. If the underlying data is weak, incomplete, outdated, inconsistent, or not fit for the intended task, the outcome will still be weak.
The technical mechanism changes. The dependency on data quality does not.
A simple example makes this clear.
Imagine the authoritative refund policy is missing, and only an outdated version is available.
In a RAG setup, the system may retrieve the wrong chunk or miss the important exception. In a large-context setup, the system may include the outdated policy in full and still treat it as valid.
So the failure looks different, but the root problem is the same: the system does not have the right data in the right quality.
That is why I think the deeper question is usually not:
RAG or long context?
vector database or graph database?
tool call or prompt?
agent or no agent?
The deeper question is this:
Is the data fit for the task the AI system is supposed to solve?
More context does not automatically mean better context.
3. Data quality in the AI era
For me, data quality in AI means this:
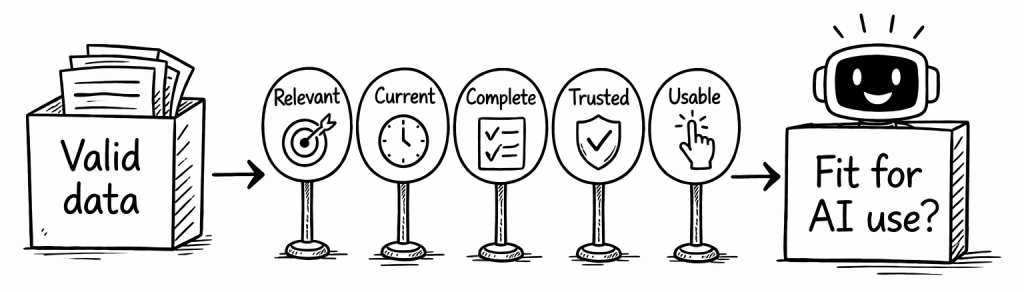
Data quality means that the data is fit for the intended AI use case.
That sounds simple, but it includes many dimensions.
In classical IT, data quality is often discussed in terms such as correctness, completeness, and consistency. These dimensions still matter in AI systems. But in the AI era, they are no longer enough on their own.
We also need to ask whether the data is relevant for the actual task, whether it includes the important exceptions, whether it comes from a trustworthy source, whether it is still current, and whether it can be used reliably inside an AI pipeline.
In other words, data quality in AI is not only about whether data exists.
It is about whether the data is good enough for the decision, answer, or action the system is expected to support.
In this metaphor, the cup represents the delivery structure around the answer:
The agent
The MCP server
The vector database
The graph database
The prompt
The orchestration
But the value is still in the coffee. And in AI systems, the coffee is the data.
3.1 Relevant dimensions of data quality
These are some example dimensions of data quality.
3.1.1 Relevance
Does the data actually help answer the user’s question? A system can have a lot of data and still fail, because the data is not relevant to the actual task.
3.1.2 Correctness
Is the content factually correct? Wrong facts, wrong versions, wrong mappings, or wrong extracted values directly damage the result.
3.1.3 Completeness
Does the data include the important cases and exceptions? This is often where practical systems fail. The main rule is present, but the exception is missing.
3.1.4 Consistency
Do all sources say the same thing? If one source says one thing and another says something else, the AI system may choose one without understandingthe conflict.
3.1.5 Timeliness
Is the data still current? Old policy documents, old product descriptions, or outdated process steps can produce very confident but wrong answers.
3.1.6 Traceability
Do we know where the data came from? If we cannot trace the source, it becomes difficult to justify trust.
3.1.7 Ownership
Do we know who owns the data and who maintains it? This is a very practical question. If nobody owns the data, quality usually degrades over time.
3.1.8 Integrity
Has the data been compromised, manipulated, or damaged? This matters especially if data is copied across systems, transformed multiple times, or extracted from poor input formats.
3.1.9 Usability for AI
Can the AI pipeline actually use the data reliably? A human-readable PDF is not automatically AI-ready data. A table in Excel may look clear to a person, but extraction can flatten or distort its meaning.
4. What is golden data?
A useful and practical term here is golden data. Golden data is the most trusted and authoritative version of data for a specific purpose. It is the data that defines what the correct answer should be. It is not simply the newest document, but the source that should govern the decision for that use case.
In other words, golden data represents the source of truth for a given task.
For example:
The official refund policy, not an old slide deck
The approved product specification, not a copied wiki page
The maintained support procedure, not an email thread
The valid contract terms, not someone’s summary
Humans inside an organization often know which source is authoritative. AI systems usually do not. They only see the data that is made available through documents, retrieval pipelines, context windows, APIs, or tools.
If multiple sources exist and the authoritative one is not clearly identified, the system may retrieve the wrong one.
That is why identifying and exposing golden data is a key design step when building AI systems.
A simple situation illustrates the problem. Imagine an AI assistant retrieves five documents about refunds:
Last year’s policy
This year’s updated policy
A support wiki page summarizing the rule
A training slide deck
A legal document describing campaign exceptions
To a human, it may be obvious that the updated legal policy is the authoritative source.
To the AI system, all five documents may simply look like “relevant text”. If we do not clearly identify the golden source, the system may retrieve the wrong one. The answer may still sound fluent and confident — but it may be wrong. That is why identifying golden data is one of the most important design steps when building AI systems.
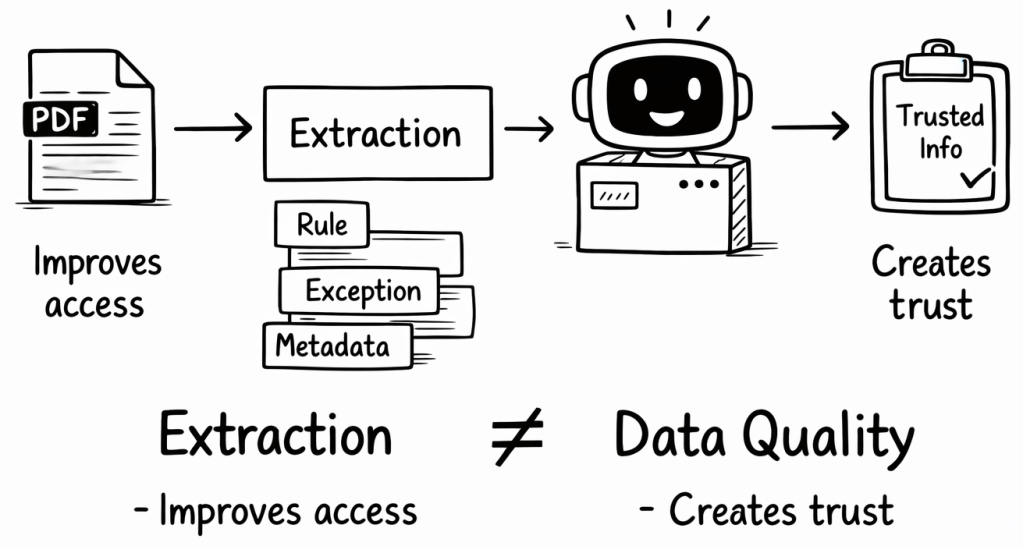
Extraction increases access to data — but it does not create data quality.
5. Tools like Docling help a lot — but they do not solve the whole problem
Today, tools like Docling make it much easier to extract content from PDFs, Word documents, PowerPoint files, and Excel sheets and prepare it for AI pipelines.
This is a significant step forward.
It improves access to enterprise knowledge that was previously difficult to use in AI systems. However, extraction is not the same as data quality. Even when extraction works well, several important questions remain:
Was the document structure preserved?
Was a table interpreted correctly?
Did footnotes stay connected to the rules they modify?
Was OCR accurate?
Was the newest document version used?
Is the extracted document actually the authoritative source?
Consider a simple situation.
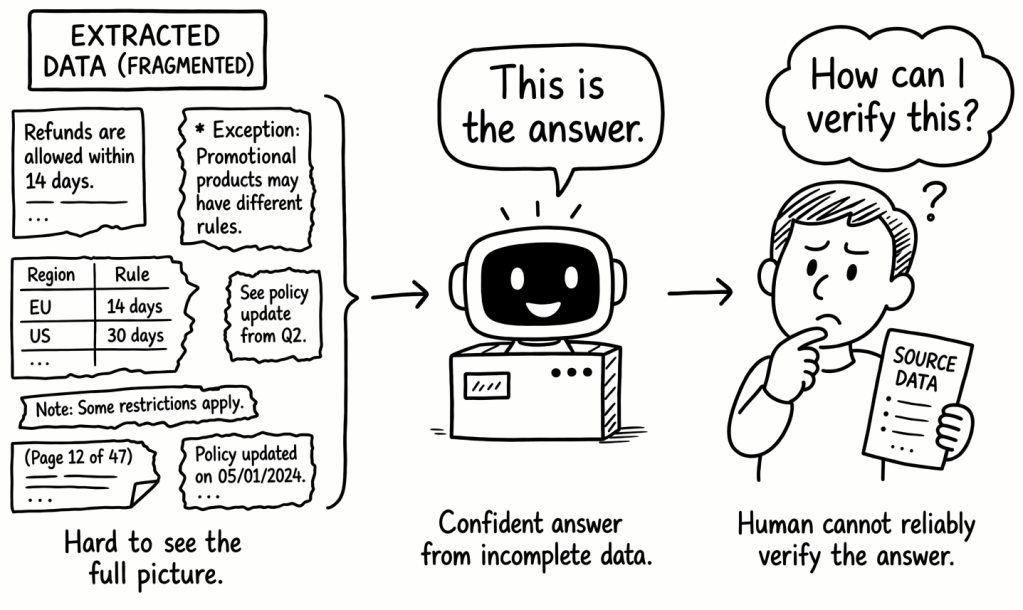
A refund policy exists as a structured PDF document. The main rule is defined in a table, and an exception is written in a footnote. After extraction, the AI pipeline may store:
The main rule as one text chunk
The exception as a separate chunk
The metadata as another fragment
Technically, the extraction worked. But the relationship between the rule and the exception may no longer be clear. The system now has more accessible information, but not necessarily more reliable information. Tools like Docling therefore remove an important barrier: they make enterprise knowledge accessible to AI systems.
But they do not automatically guarantee:
Correctness
Completeness
Authority
Trustworthiness
Extraction improves access to data. But access is not the same as quality. Even a strong AI architecture cannot compensate for weak, ambiguous, or non-authoritative data.
6. A simple example from beginning to end
Let me use a simple example.
Imagine a company wants to build an AI assistant for customer support.
A customer asks:
“Can I return this product and get a full refund?”
The company builds a modern AI architecture:
Documents are extracted with Docling
Chunks are stored in a vector database
A graph database stores product and policy relationships
An MCP server exposes support tools
An agent answers the user
On paper, this architecture looks strong.
6.1 The available data
The company has several documents:
A refund policy PDF from last year
An updated refund policy PDF from this year
An Excel file with regional exceptions
A support wiki page
A legal document for promotional products
A few email clarifications between teams
Immediately the first data-quality question appears:
Which source is the real source of truth?
This is not an architecture problem.
It is a data governance problem.
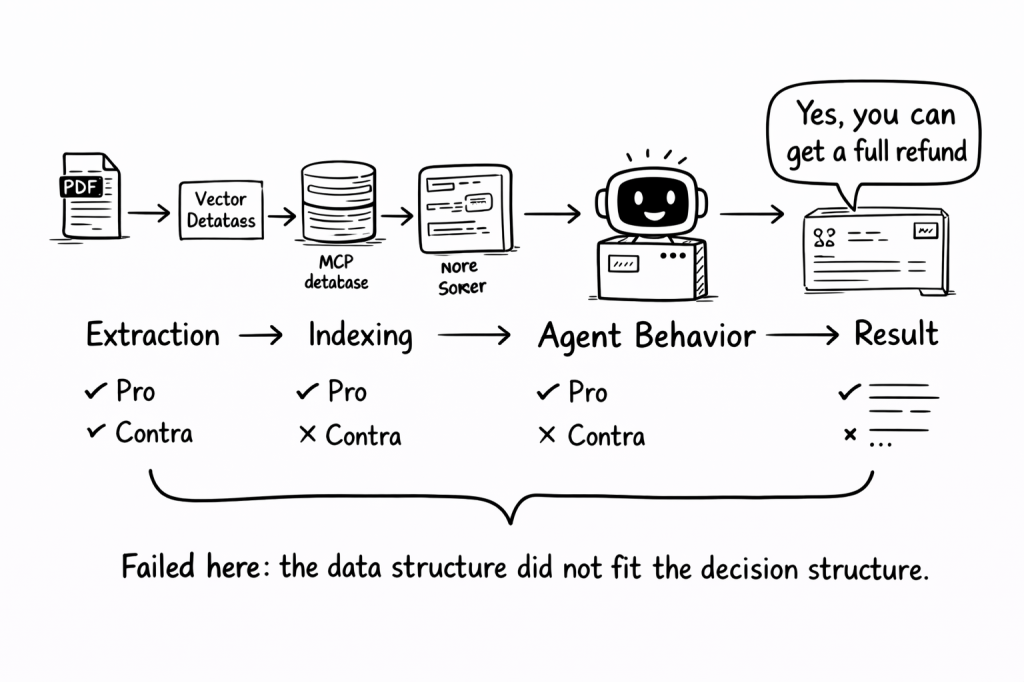
Step 1 — Extraction
The documents are processed and extracted.
Pros
Content becomes accessible
Data from PDFs and spreadsheets enters the pipeline
Information can be indexed and searched
Hidden enterprise knowledge becomes usable
Cons
Table structures may be flattened
Headers and exceptions may lose context
OCR may introduce errors
Version information may not be captured clearly
Legal notes may detach from the main rule
At this stage the system may become technically richer but semantically weaker.
Step 2 — Chunking and indexing
The extracted text is chunked and stored.
Pros
Retrieval becomes faster
Relevant passages can be found
Embeddings connect similar meanings
AI can answer beyond keyword matching
Cons
The main rule may land in one chunk
The exception may land in another chunk
The system may retrieve only the main rule
Outdated chunks may rank highly
Metadata may not prioritize authoritative documents
This is a very common failure pattern.
The AI does not fail because it cannot generate language.
It fails because the structure of the data no longer matches the structure of the decision logic.
Step 3 — Agent behavior
Now the agent receives the user question:
“I bought a discounted product in Germany last week. Can I still get a full refund?”
To answer correctly the system needs:
The main refund policy
The rule for discounted products
The Germany-specific exception
The time rule
The newest version of the policy
Pros
The agent can combine multiple sources
Tools can gather additional details
Graph relations can connect product, country, and policy
The system provides natural language explanations
Cons
If one key exception is missing, the answer becomes wrong
If the wrong source is treated as authoritative, the answer still sounds correct
Users may trust the result even when the system lacks complete information
Additional system components can hide data weaknesses behind technical complexity
Step 4 — The result
The AI answers:
“Yes, you can get a full refund within 14 days.”
The answer sounds clear and professional.
But the correct answer should have been:
“No. Discounted products in Germany under this campaign are excluded from the standard refund policy.”
So what failed?
Not necessarily:
The model
The vector database
The graph database
The MCP server
The agent concept
Docling itself
What failed was the fit between the data and the decision.
The system produced a fluent answer from incomplete knowledge.
7. What this example shows
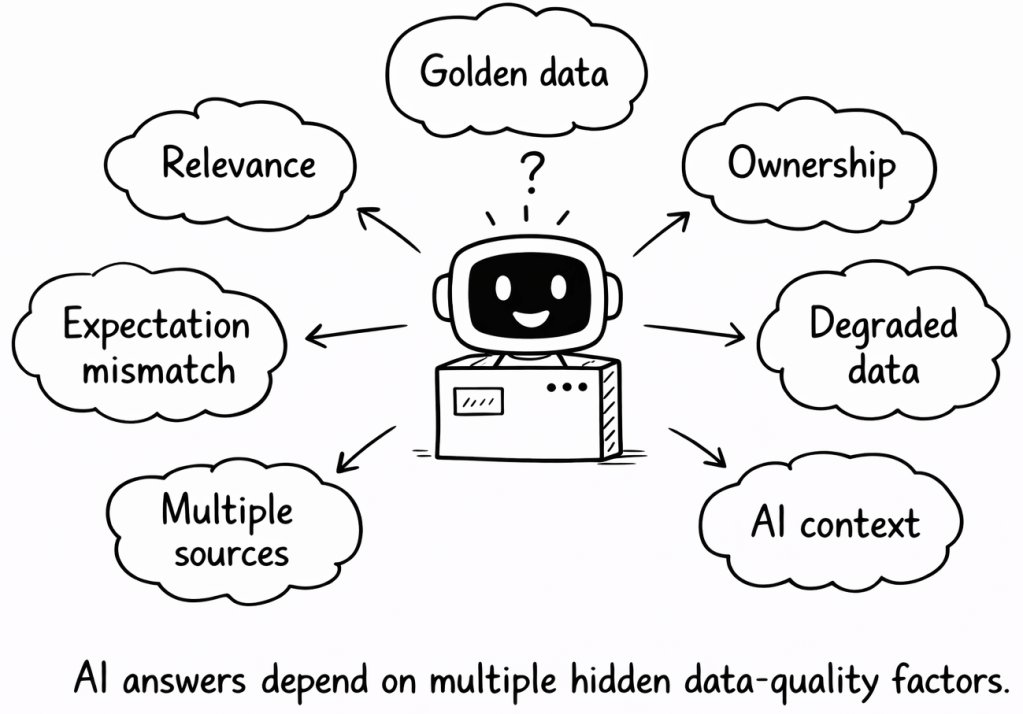
This simple scenario highlights many of the most important data-quality challenges in AI systems.
The problem was not a missing architectural component. The system already had extraction, indexing, retrieval, and an agent.
The real problem was the relationship between the data, the decision, and the user expectation.
7.1 Relevance
The system needs policy data, not just general support content.
If the retrieved information does not match the user’s specific situation, the answer may still sound plausible but remain incorrect.
7.2 Golden data
The system must know which document is authoritative.
If several documents describe the same rule, but only one is the official policy, the AI system needs to treat that document as the primary source.
7.3 Mismatch between data and expectation
The user expects a correct decision.
But the system may only have partial supporting material.
If the data does not fully cover the decision logic, the system may produce a fluent answer based on incomplete information.
7.4 Ownership
Someone must own and maintain the policy data.
Without clear ownership, rules, exceptions, and updates often become fragmented across documents and teams.
Over time, the knowledge base becomes inconsistent.
7.5 Compromised or degraded data
Data can degrade even without malicious intent.
Extraction, copying, chunking, and transformation may weaken the relationship between rules and exceptions.
The meaning of the information may become less clear even though the text still exists.
7.6 Who collects the data
Enterprise knowledge rarely comes from a single source.
Legal teams, support teams, regional teams, and sales teams may all contribute pieces of information.
Each group may document rules differently and with different assumptions.
7.7 AI context
The same data behaves differently depending on how it is used:
RAG retrieval
Long context prompts
Graph retrieval
Agent workflows
Tool responses
Data quality therefore cannot be evaluated independently from the AI usage context.
8. Why the same data performs differently across AI architectures
Another important observation is that data quality cannot be evaluated independently from the AI architecture that uses the data.
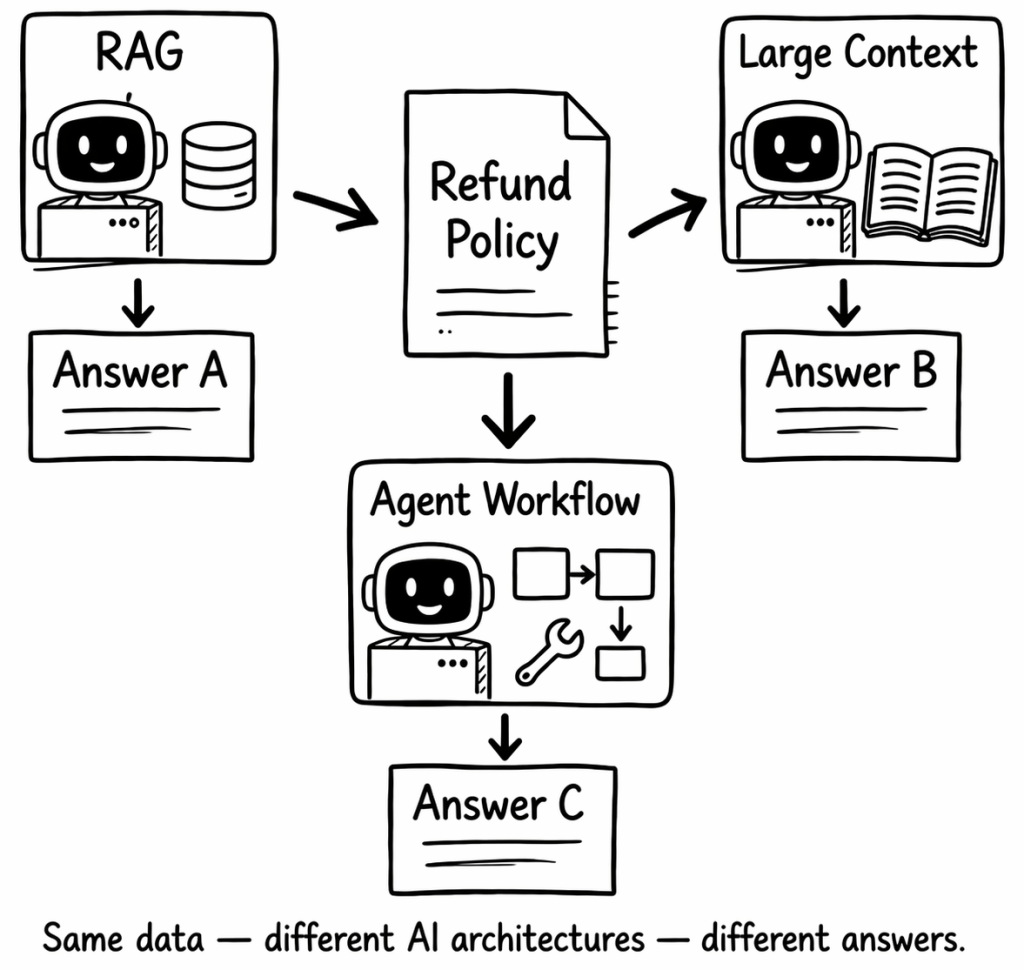
The same dataset can perform well in one setup and poorly in another.
This means that data quality is not only about the data itself — it is also about how the AI system interacts with that data.
To illustrate this, consider the refund-policy example from earlier.
The same documents are used, but the system architecture changes.
8.1 In a long context prompt
In a large-context setup, the AI model may receive an entire policy document.
Pro
The main rule and its exceptions may remain close together
The model can see surrounding explanations and legal wording
The system may better understand relationships inside the document
Contra
Outdated and current policies may appear together
Irrelevant sections can dilute the answer
The model must decide which rule is valid without strong signals
8.2 In RAG
In a retrieval-based system, the model receives only selected chunks.
Pro
Retrieval can focus on relevant passages
Large knowledge bases remain scalable
Irrelevant content can be filtered out
Contra
An exception may live in a different chunk and not be retrieved
Ranking may prefer an outdated policy section
The retrieved context may miss the rule that modifies the answer
8.3 In an agent workflow
In an agent-based architecture, multiple tools and steps may be involved.
Pro
The system can query additional sources
Tools can gather structured information
Reasoning steps can combine different pieces of knowledge
Contra
users may trust the result more than they should
missing or weak data can propagate through several steps
the final answer may look more convincing because the process appears complex
9. Summary
I think this topic will become more important, not less.
Today we are building increasingly sophisticated AI systems with powerful technical components:
Agents
MCP servers
Vector databases
Graph databases
Large context windows
Document extraction pipelines
These systems represent real technical progress. But the deeper question remains the same: What data is actually inside the cup?
If the data is weak, incomplete, outdated, unowned, badly extracted, inconsistent, or disconnected from the real task, the AI system will remain unreliable.
Modern architecture can improve access to data. It can improve reasoning. It can improve interaction.
But it cannot replace missing, incorrect, or poorly governed data.
That is why data quality is not a side topic in the AI era.
It is one of the core design questions.
Because in the end:
The cup is not the coffee.
But without a good cup you cannot drink the coffee — and without good coffee, the cup has no value.
Reliable AI systems require both.
10. References
Patrick Lewis et al. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. arXiv. https://arxiv.org/abs/2005.11401
Yunfan Gao et al. (2024). Retrieval-Augmented Generation for Large Language Models: A Survey. arXiv. https://arxiv.org/abs/2312.10997
Note: This post reflects my own ideas and experience; AI was used only as a writing and thinking aid to help structure and clarify the arguments, not to define them.




Also interesting topic (Data Quality of Service (Data QoS): https://medium.com/data-mesh-learning/what-is-data-qos-and-why-is-it-critical-c524b81e3cc1
LikeLike