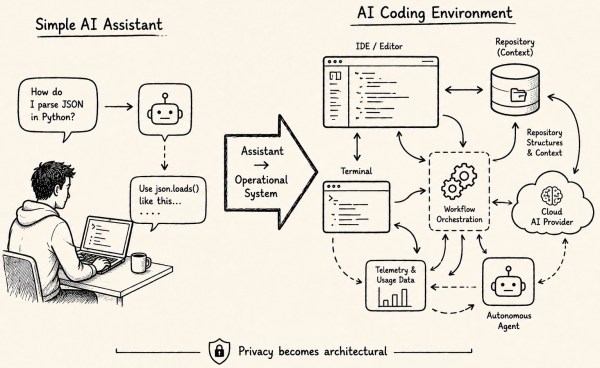
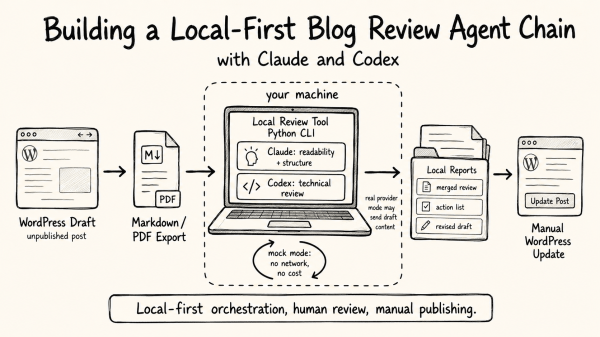
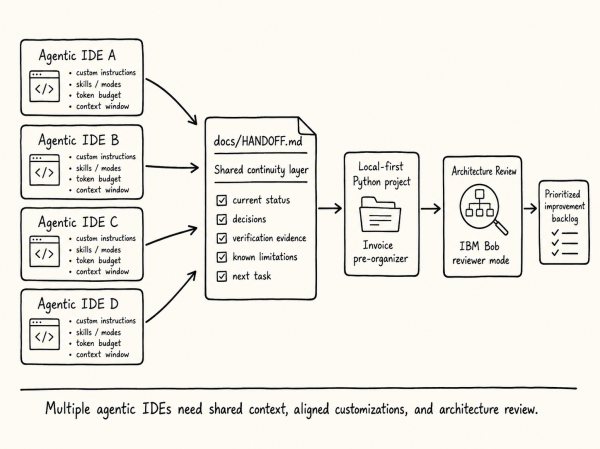
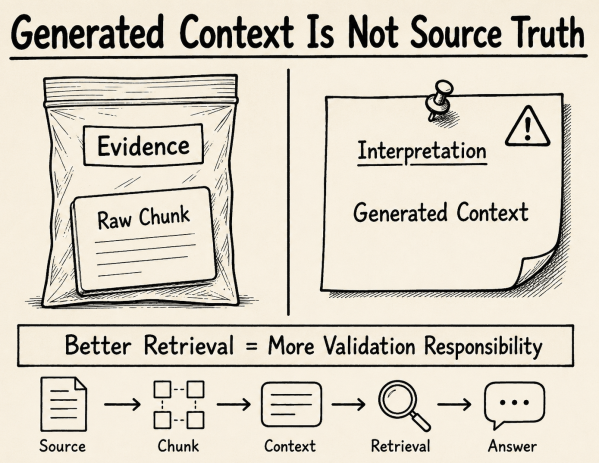
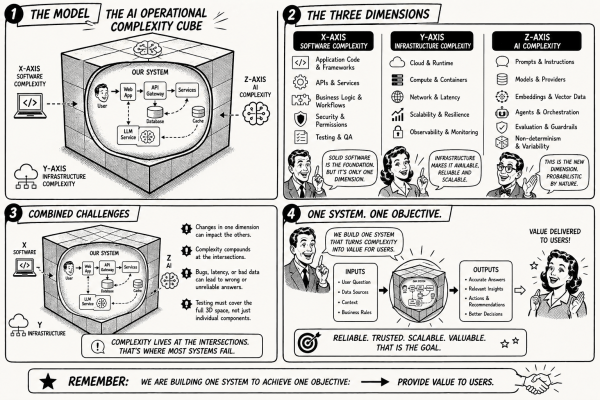
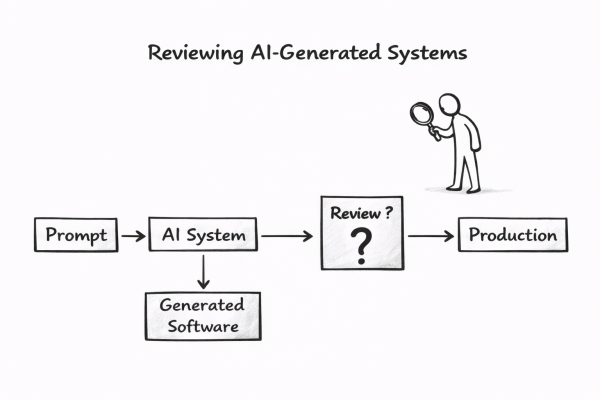
The AI generated explores the complexities of privacy in the context of AI coding assistants and agentic IDEs. It emphasizes that privacy is now a structural choice within development environments rather than a simple policy acceptance. The effectiveness of six platforms is assessed based on their privacy features, highlighting trade-offs between integration, cost, and data handling.
AI generated Podcast Episode: AI Coding Assistants, Agentic IDEs, and Privacy: From Chatbots to Operational Systems