
- Comparing ChatGPT, Claude, Gemini, GitHub Copilot, IBM Bob, and local Granite models from a private developer perspective
- Privacy as Data Sovereignty
- Privacy Depends on the Threat Model
- The Most Important Clarification
- Relative Privacy Exposure
- Execution and Privacy Architecture Comparison
- Important Legal and Privacy Statements
- Local Granite Models Or Other OpenSource
- IBM Bob
- Claude
- OpenAI and Local Models
- Gemini and Local Models
- GitHub Copilot and Local Models
- A Very Important Difference
- Consumer Pricing Comparison
- Normalized Consumer Pricing
- IBM Bobcoin Conversion Details
- What the Price Comparison Reveals
- Privacy, Ownership, and Open Knowledge
- Final Thoughts
- References
1. Comparing ChatGPT, Claude, Gemini, GitHub Copilot, IBM Bob, and local Granite models from a private developer perspective
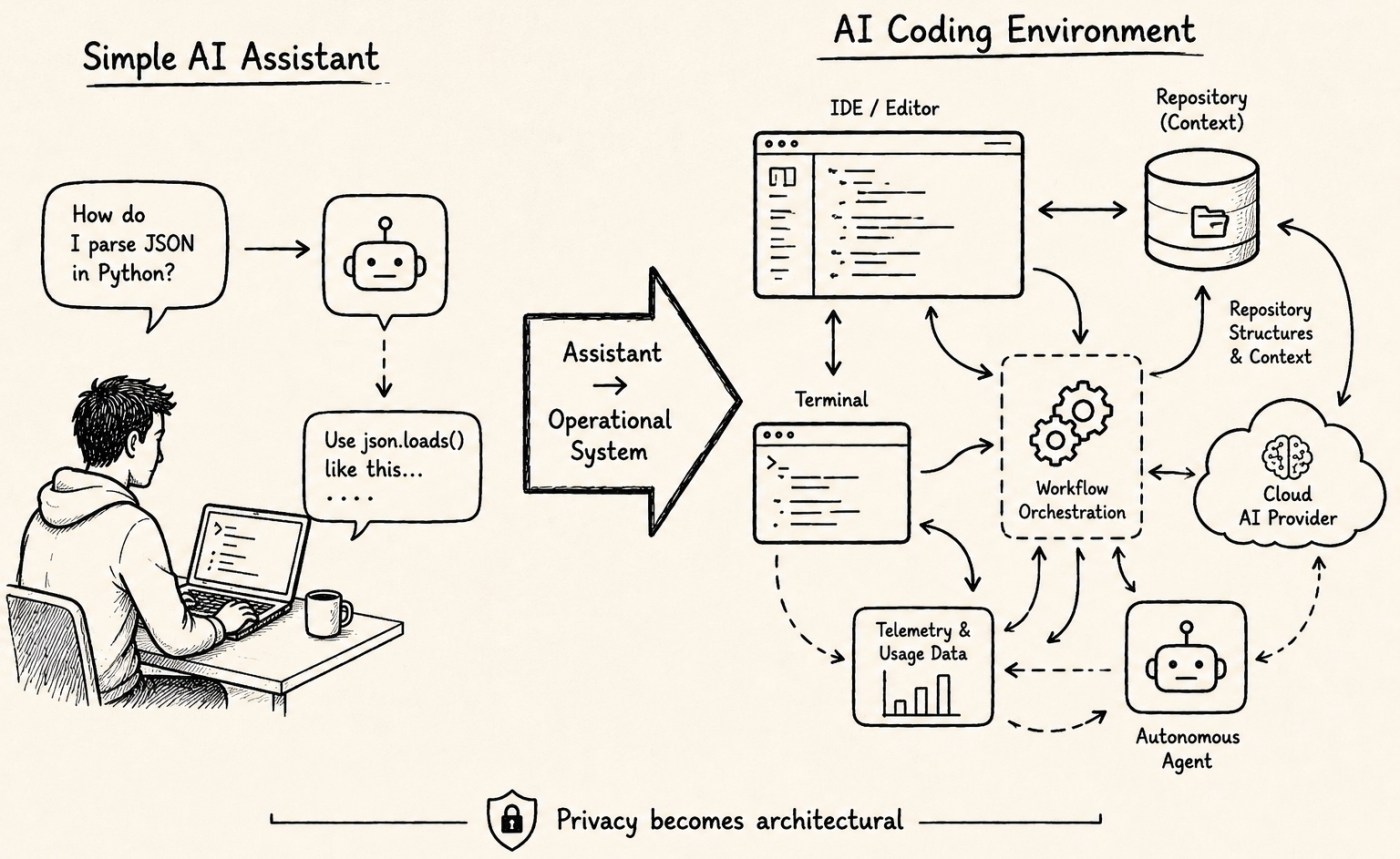
For almost a year, I found myself increasingly thinking about a topic that many AI discussions still underestimate or just now coming up:
What exactly happens with our prompts, code, repositories, terminal commands, and development context?
As a developer, I noticed that modern AI tooling is no longer just about:
- asking questions
- generating snippets
- chatting with an LLM
AI systems are increasingly becoming:
- development environments
- repository assistants
- workflow orchestrators
- autonomous coding agents
That changes the privacy discussion completely.
This post focuses only on:
- private users
- hobby developers
- freelancers
- individual developers
using officially available consumer offerings.
This is not an enterprise comparison.
This comparison reflects the current publicly documented state and may change as products, integrations, and policies evolve.
The investigation is based mainly on:
- Terms of Service
- Privacy Policies
- User Agreements
- Data Usage Policies
- Pricing Models
- Official product documentation (that means Out-Of-The-Box OOTB functionality available by each product)
Keep in Mind:
Policies and technical implementations may change over time.
This post reflects the publicly documented state at the time of writing.
2. Privacy as Data Sovereignty
One important realization during this investigation was:
Privacy is no longer just a checkbox.
It is increasingly becoming an architectural design decision of your development environment for the entire SDLC.
In this post, privacy mainly means:
- data sovereignty
- control over prompts and repositories
- visibility into processing
- telemetry exposure
- where AI execution actually happens
Many discussions still only ask:
- “Does the provider train on my data?”
But modern AI coding systems may additionally process:
- repository structures
- IDE context
- terminal commands
- uploaded files
- telemetry
- generated code
- workflow metadata
- cloud execution environments
This means:
privacy is no longer only about model training.
It is also about:
- retention
- logging
- routing
- context visibility
- operational exposure
Local execution can improve sovereignty and reduce external operational exposure.
However, local execution alone does not automatically guarantee security.
Endpoint security, credential protection, and repository governance remain separate concerns.
2.1 Privacy Depends on the Threat Model
The effective privacy situation depends strongly on the individual threat model.
A hobby developer experimenting with public repositories may evaluate risk very differently from:
- freelancers working with customer-owned code and data
- developers working under NDA constraints
- security researchers
- regulated industries
- enterprise environments
Therefore, there is no universally “best” AI coding assistant/agent from a privacy perspective.
The relevant question is:
Which operational exposure is acceptable for the specific workflow and context, during usage in the SDLC?
3. The Most Important Clarification
One important clarification became necessary during this investigation:
“Cloud-based” does NOT automatically mean “no local models.”
There are actually two different questions:
| Question | Meaning |
|---|---|
| Where does the official main model run? | Is the normal product cloud-hosted or local-first? |
| Can local models be integrated? | Can the system connect to Ollama, self-hosted models, or local providers? |
This distinction is important because some products are:
- cloud-first by default,
- but still support local/self-hosted integrations in specific workflows
4. Relative Privacy Exposure
This section reflects my current technical interpretation for private developer workflows based on publicly documented consumer offerings and documented integration possibilities.
It is not a security audit, legal certification, or formal privacy assessment.
The effective privacy situation depends strongly on:
- workflow configuration
- routing architecture
- telemetry settings
- repository integration
- local vs cloud execution
- the individual threat model
| Rank | Platform | Privacy Situation for Private Users |
|---|---|---|
| 1 | Local Hosted Model for Example Granite (using Ollama etc.) | Strongest technical isolation |
| 2 | IBM Bob | Strong no-training statement, but cloud-first |
| 3 | Claude | More privacy-focused wording and configurable routing |
| 4 | ChatGPT / OpenAI | Complex multi-layer privacy architecture |
| 5 | Gemini | Strong ecosystem integration and activity tracking |
| 6 | GitHub Copilot | Deep IDE and repository integration |
5. Execution and Privacy Architecture Comparison
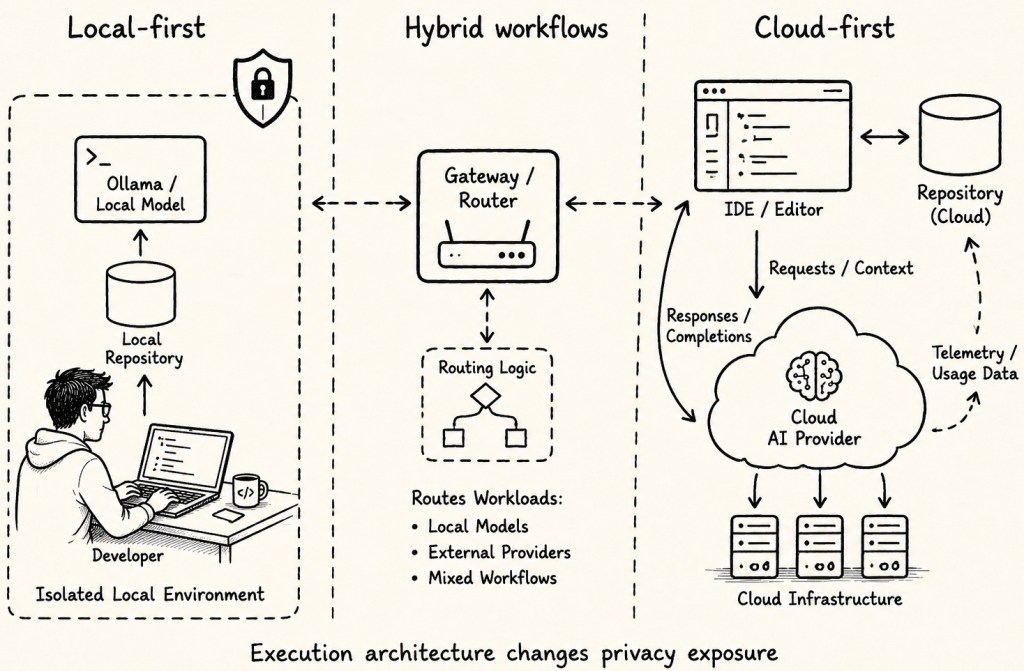
This diagram compares three different AI coding execution architectures and their privacy exposure levels:
- Local-first workflows keep repositories, prompts, and models inside an isolated local environment.
- Hybrid workflows use gateways and routing logic to combine local models with external AI providers.
- Cloud-first workflows integrate IDEs, repositories, and AI providers through cloud infrastructure with telemetry and operational visibility.
The central idea:
Execution architecture directly influences privacy exposure in modern AI-assisted software development related to the table below.
| Platform | Default Model Execution | Local Models Possible? | Repository / IDE Access | Cloud-Based by Default |
|---|---|---|---|---|
| Local Model for Example Granite + Ollama | Local-first | Yes | Optional | No |
| IBM Bob | Cloud-first | No officially documented local backend found for private users | Yes | Yes |
| Claude / Claude Code | Cloud-first | Yes, via routing/gateway workflows | Increasingly yes via tools | Yes |
| ChatGPT / OpenAI | Cloud-first | Separate open models exist | Increasingly yes via tools/Codex | Yes |
| Gemini | Cloud-first | Separate Gemma models exist | Limited (Limited direct VS Code integration in typical consumer workflows.) | Yes |
| GitHub Copilot | Cloud-first | Yes in BYOK/local workflows | Strong | Yes |
6. Important Legal and Privacy Statements
This section contains direct quotes from official provider documentation.
6.1. Local Granite Models Or Other OpenSource
6.1.1 Why Granite Local Or Other OpenSource Model Is Different
Granite or other OpenSource models (example HuggingFace) itself is not a cloud service. The open-source model family that can run:
- locally
- offline
- self-hosted
- inside private infrastructure
This changes the entire privacy situation.
If you run Granite locally using:
then prompts and code stay inside your environment unless external services are configured manually.
IBM documents local VS Code workflows using:
- Granite (with watsonx Code Assistant) with Ollama or Continue. [8]
That is fundamentally different from cloud AI systems.
6.1.2 Privacy Position
| Topic | Situation |
|---|---|
| Model Training | No external training possible locally |
| Data Transfer | None by default |
| Repository Exposure | Fully controlled locally |
| Cloud Dependency | None |
6.2. IBM Bob
IBM Bob became interesting because IBM uses one of the clearest public statements in this comparison.
IBM states:
“Your prompts are not used as training data.” [1]
This is an important and unusually direct statement.
However, this statement does NOT automatically prove:
- zero telemetry
- zero retention
- zero logging
- zero operational monitoring
I also could not find official consumer-facing documentation that clearly states:
- private users can replace the IBM Bob backend with local Ollama-style model execution.
Therefore, IBM Bob should currently be classified as:
- cloud-first
- with a strong no-training statement
- but not as a local-first architecture
More precisely:
- local backend support is currently not officially documented for private users based on the sources I could verify.
Note: Bob provides an opt out option for collecting usage data. See the image below.

6.2.1 IBM Bob Privacy Summary
| Topic | Situation |
|---|---|
| Model Training | IBM states no |
| Logging / Retention | Not fully documented publicly |
| Local Execution | No officially documented local backend found |
| Cloud Processing | Yes |
6.3. Claude
Anthropic’s wording is more privacy-focused than many competitors.
Anthropic states:
“We will not train our generative models using your personal information unless you give us your consent.” [2]
This wording is important because it differs from many standard consumer AI services.
However, Anthropic also documents:
- safety review processes,
- abuse monitoring,
- and configurable privacy settings.
6.3.1 Claude and Local Models
Claude as a consumer chat product is cloud-first.
However, Claude Code introduces more flexible workflows.
Anthropic documents:
- LLM gateway support,
- configurable routing,
- external providers. [9]
Additionally, Ollama documents Anthropic-compatible local model workflows with Claude Code. [10]
This means:
Claude is not local-first,
but it can participate in local/self-hosted workflows.
6.3.2 Claude Privacy Summary
| Topic | Situation |
|---|---|
| Training Usage | Possible depending on settings |
| Opt-Out | Yes |
| Local Routing Possible | Yes |
| Cloud Processing | Yes |
6.4. ChatGPT / OpenAI
OpenAI’s privacy structure is currently one of the most complicated systems in this comparison.
Why?
Because OpenAI separates:
- ChatGPT Consumer
- API
- Enterprise
- Codex
- Full Environment Access
- Tool Integrations
- Open Models
OpenAI states:
“When you use our services for individuals such as ChatGPT, we may use your content to train our models.” [3]
However, OpenAI also states for API usage:
“By default, we do not use content submitted by customers to our business offerings such as our API to improve model performance.” [4]
6.4.1 OpenAI and Local Models
The normal ChatGPT application remains cloud-first.
However, OpenAI now also publishes open-weight/open models. [11]
This creates an important distinction:
| Product | Situation |
|---|---|
| ChatGPT | Cloud-first |
| OpenAI Open Models | Can run elsewhere/self-hosted |
These should not be treated as the same deployment model.
6.4.2 ChatGPT Privacy Summary
| Topic | Situation |
|---|---|
| Training Usage | Yes by default |
| Opt-Out | Yes |
| API Isolation | Yes |
| Codex Special Controls | Yes |
| Open Models Exist | Yes |
| Cloud Processing | Yes |
6.5. Gemini
Google Gemini is strongly connected to the Google ecosystem, even in the private plan options.
Google documents that Gemini interactions may be reviewed and used for AI improvement.
Google states:
“To help improve Gemini Apps, your conversations may be reviewed by human reviewers.” [5]
Google also explains:
activity history can be disabled, but temporary retention may still occur.
6.5.1 Gemini and Local Models
Gemini itself is cloud-first.
However, Google separately publishes:
- Gemma open models. [12]
This creates a similar situation to OpenAI:
| Product | Situation |
|---|---|
| Gemini App | Cloud-first |
| Gemma Models | Can run locally |
Again:
these are different product categories.
6.5.2 Gemini Privacy Summary
| Topic | Situation |
|---|---|
| Training Usage | Yes |
| Opt-Out | Partial |
| Human Review | Yes |
| Local Open Models Available Separately | Yes |
| Cloud Processing | Yes |
6.6 GitHub Copilot
GitHub Copilot is technically one of the most deeply integrated systems in this comparison.
Why?
Because it is deeply integrated into:
- IDEs
- repositories
- project structures
- workflows
- coding environments
Important: GitHub documents that prompts and related interactions may be used for product improvement for individual subscriptions.
GitHub states:
“GitHub Copilot Individual may collect and retain prompts, suggestions, and engagement data.” [6]
6.6.1 GitHub Copilot and Local Models
GitHub Copilot is cloud-first by default.
However, GitHub now documents:
- Bring Your Own Key (BYOK),
- custom model routing,
- and local/self-hosted model workflows in Copilot CLI. [13]
VS Code also documents support for locally hosted models via supported providers. [14]
This means:
GitHub Copilot is no longer a purely “GitHub-hosted only” environment.
Its privacy profile now depends strongly on:
- the selected workflow,
- the model provider,
- and the routing architecture.
6.6.2 GitHub Copilot Privacy Summary
| Topic | Situation |
|---|---|
| Training Usage | Possible |
| Opt-Out | Yes |
| Repository Context Access | Strong |
| IDE Integration | Strong |
| Local Model Workflows Possible | Yes |
| Cloud Processing | Yes |
7. A Very Important Difference
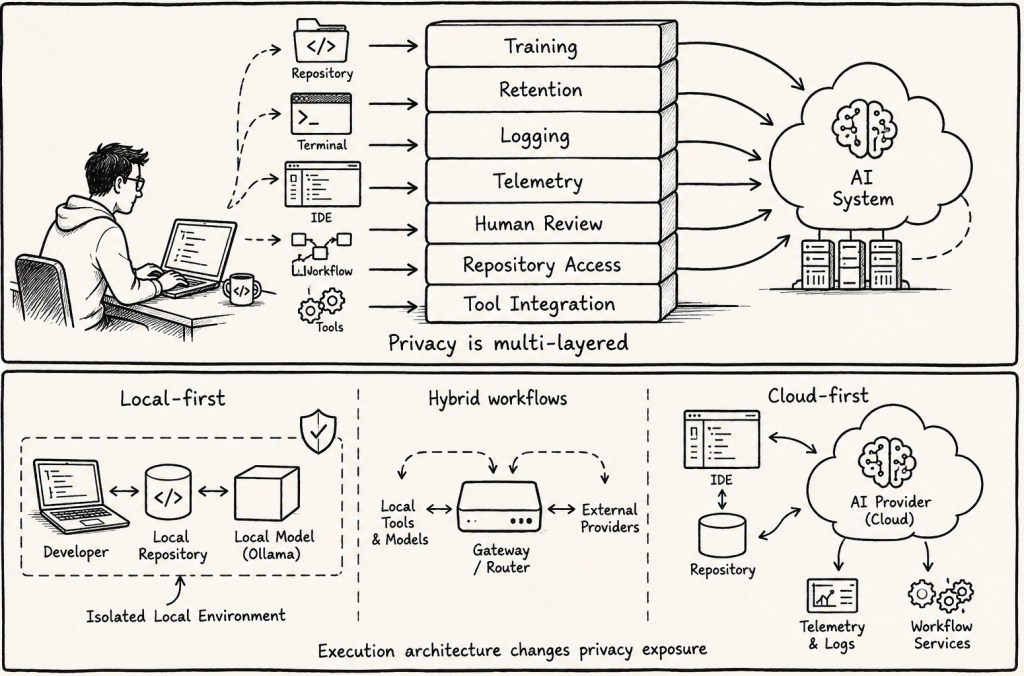
During this investigation, one thing became extremely clear:
“Not used for training” does NOT automatically mean “private.”
There are several different layers:
| Layer | Meaning |
|---|---|
| Training | Used to improve models |
| Retention | Stored temporarily |
| Logging | Operational tracking |
| Telemetry | Usage and behavioral metrics |
| Human Review | Manual inspection |
| Repository Context | Access to development structures |
| Tool Integration | Access to workflows and commands |
Many users only focus on:
- model training
But modern AI coding/agent systems increasingly behave like:
- cloud IDEs
- repository agents
- orchestration systems
- autonomous development assistants
That changes the privacy discussion significantly.
8. Consumer Pricing Comparison
To make IBM Bob comparable with the other offerings, I converted the published Bobcoin values into approximate USD equivalents using IBM’s own conversion information.
IBM documents:
- 1 Bobcoin = 0.50 USD. [7]
The following table therefore normalizes the pricing across all investigated consumer offerings.
8.1 Normalized Consumer Pricing
| Platform | Consumer Plan | Approximate Monthly Price | Privacy Situation |
|---|---|---|---|
| Granite or OpenSource Local | Self-hosted | Hardware cost only | Strongest technical isolation |
| IBM Bob | Pro | ~20 USD equivalent | Strong no-training statement |
| IBM Bob | Pro+ | ~80 USD equivalent | Higher Bobcoin usage package |
| IBM Bob | Ultra | ~250 USD equivalent | Highest Bobcoin usage package |
| Claude | Pro | ~20 USD/month | Better privacy wording |
| Claude | Max | ~100 USD/month | Higher usage tier |
| ChatGPT | Plus | ~20 USD/month | Complex data usage layers |
| Gemini | Advanced / AI Pro | ~20 EUR/month | Strong ecosystem integration |
| GitHub Copilot | Pro | ~10 USD/month | Lowest price, deepest IDE exposure |
8.2 IBM Bobcoin Conversion Details
| IBM Bob Plan | Included Bobcoins | Conversion Formula | Approximate USD Equivalent |
|---|---|---|---|
| Pro | 40 Bobcoins | 40 × 0.50 USD | ~20 USD |
| Pro+ | 160 Bobcoins | 160 × 0.50 USD | ~80 USD |
| Ultra | 500 Bobcoins | 500 × 0.50 USD | ~250 USD |
This conversion is only used to create a more transparent comparison with the subscription pricing of the other providers.
8.3 What the Price Comparison Reveals
This comparison makes something interesting visible:
| Lower Price | Higher Price |
|---|---|
| Often more data exposure | Often more governance |
| Consumer convenience | Better control |
| Default cloud behavior | More isolated environments |
However, the relationship is not always linear.
For example:
- GitHub Copilot is relatively inexpensive
- but has very deep repository and IDE integration
Meanwhile:
- local Granite execution may require expensive hardware,
- but provides the strongest technical privacy isolation.
This means:
the real “price” of AI systems is not only money.
Users may additionally “pay” with:
- prompts,
- repository context,
- telemetry,
- workflow visibility,
- and operational exposure.
Note: The basic statement you may know is “If you don’t pay for the product… you are the product.” , but now we can say: “If you pay for a product, but you don’t pay enough … then you are still the product ;-)”
9. Privacy, Ownership, and Open Knowledge
While working on this comparison, I increasingly realized that AI coding assistant/agent privacy is connected to another topic I explored in earlier posts: ownership and open knowledge.
Modern AI coding assistants no longer process only simple prompts.
They may process:
- repositories
- architecture decisions
- terminal commands
- workflow metadata
- product ideas
That means developer context itself may contain economically valuable knowledge.
In my earlier post about AI-generated software patents and global IP law, I reflected on how AI-assisted software development creates new uncertainty around authorship, inventorship, and human contribution:
AI-generated software patents and global IP law – a first deep dive using AI
In another post, I reflected on a related paradox:
AI became powerful because of open-source software, public repositories, blogs, tutorials, and shared knowledge.
But its economic success may also reduce the willingness to share knowledge openly in the future:
AI grew on open knowledge — will its success end that openness?
For me, this adds another dimension to AI coding assistant privacy.
Privacy is no longer only about hiding data.
It is increasingly also about:
- protecting unfinished ideas,
- controlling operational visibility,
- preserving human contribution,
- and deciding intentionally how much developer knowledge should become part of AI-visible workflows.
The future question may not only be which AI coding assistant/agent is more private, but also how much developer knowledge we are willing to expose to systems that can transform context into economic value.
10. Final Thoughts
This is a result also of an interactive exchange with Niclas Cramer during the writing of the post.
After comparing:
- official policies
- legal wording
- technical architecture
- deployment models,
- practical workflows
my current conclusion is:
Privacy in AI coding systems is no longer a simple yes/no question.
The real questions are now:
- Is the system local or cloud-based?
- For cloud where is model hosted?
- Can local models be integrated?
- Is repository context collected?
- Is IDE activity visible?
- Is telemetry documented?
- Is human review possible?
- Are prompts retained?
- Is model training enabled?
- Is the environment autonomous?
For me, this is becoming one of the most important architectural questions in AI-assisted/agent software development.
Because modern AI coding systems are no longer simple chatbots.
They are increasingly becoming:
- software engineering environments
- workflow participants
- repository agents
- orchestration systems
And that changes the meaning of privacy completely.
11. References
[1] IBM Bob Launch Information
https://bob.ibm.com/blog/announcing-ibm-bob-launch
[2] Anthropic Privacy Center – Is my data used for model training?
https://privacy.claude.com/en/articles/10023580-is-my-data-used-for-model-training
[3] OpenAI – How your data is used to improve model performance
https://help.openai.com/en/articles/5722486-how-your-data-is-used-to-improve-model-performance
[4] OpenAI API Data Usage Policies
https://openai.com/policies/api-data-usage-policies
[5] Google Gemini Apps Privacy Help
https://support.google.com/gemini/answer/13594961
[6] GitHub Copilot Policies for Individual Subscribers
https://docs.github.com/copilot/how-tos/manage-your-account/managing-copilot-policies-as-an-individual-subscriber
[7] IBM Bobcoins Documentation
https://bob.ibm.com/docs/ide/account/bobcoins
[8] IBM Developer – Build a local AI coding assistant with IBM Granite 4, Ollama, and Continue
https://developer.ibm.com/tutorials/awb-local-ai-copilot-ibm-granite-code-ollama-continue/
[9] Anthropic Claude Code Docs – LLM gateway configuration
https://code.claude.com/docs/en/llm-gateway
[10] Ollama Docs – Claude Code integration
https://docs.ollama.com/integrations/claude-code
[11] OpenAI – Open models
https://openai.com/open-models/
[12] Google DeepMind – Gemma
https://deepmind.google/models/gemma/
[13] GitHub Docs – Using your own LLM models in GitHub Copilot CLI
https://docs.github.com/en/copilot/how-tos/copilot-cli/customize-copilot/use-byok-models
[14] VS Code Docs – AI language models in VS Code
https://code.visualstudio.com/docs/copilot/customization/language-model
Note: This post reflects my own ideas and experience; AI was used only as a writing and thinking aid to help structure and clarify the arguments, not to define them.

Leave a comment