

The post discusses the increasing integration of Large Language Models (LLMs) in applications, particularly in chat and multi-agent, highlighting how important it is to run these applications effectively in production. It reflects on the complexities introduced by LLMs compared to “older” microservices based applications (cloud native), suggesting an idea for a visual representation of this complexity within a three-dimensional cube. It emphasizes the need for comprehensive testing involving for various dimensions. That results in the following table of contents:
- Introduction
- AI Operational Complexity Cube idea
- Test Large Language Model (LLM) based Applications
- Define Test Objectives
- Create Diverse Test Cases
- Use Real-World Scenarios
- Evaluate Response Quality
- Test for Robustness
- Performance Testing
- User Testing
- Automate Testing
- Monitor and Iterate
- Ethical and Safety Testing
- Tools and Frameworks
- Summary
- Additional references and resources
1. Introduction
As software developers, IT operator, and AI engineers, you will notice testing LLM-based applications is crucial.
These days, we are seeing an increase in applications that integrate LLM. They are mostly chat applications, and we are going to use agent and multi-agent applications that use tools.
We need to ensure these applications are robust and reliable for production usage.
Revenue realization starts not with invention or innovation but with the running application in production for the proper use case.
2. AI Operational Complexity Cube idea
With my background in testing and software development life cycle (since the Rational Unified Process), I am increasingly asking myself what is different about the “older” microservices days, when the complexity of the applications and the many microservices raised the challenges for testing for end-to-end with scale to zero serverless, many containers, internal and external network, multi-clusters and so on.
Not surprisingly, the “older“ concepts of testing and test plans are still valid.
However, I wanted to highlight the differences between the older times more visually, so I came up with the idea of showing the differences in a three-dimensional cube to reflect a level of complexity and remind us that we are going.
This complexity will move us from “development/operations” (dev/ops) over “development/security/operations” (dev/sec/ops) to the new “development/machine learning/large-language-models/security/operations” (dev/(ml/LLM)/sec/ops) direction, where machine learning also includes LLMs. So, we must reflect all of this in a “continuous integration and continuous deployment/delivery” CI/CD pipeline.
So, as we can is in the diagram below, we started the complexity with an IT view related to environments and networks and a developer’s view on software and frameworks. Both views need to be secure, and every view needs to be tested (dev/sec/ops), isolated, and integrated from different angles.
The simplified diagram below reflects basic thoughts from the IT and developer perspectives.
The red dot symbolizes application complexity across the given multiple dimensions here two views.
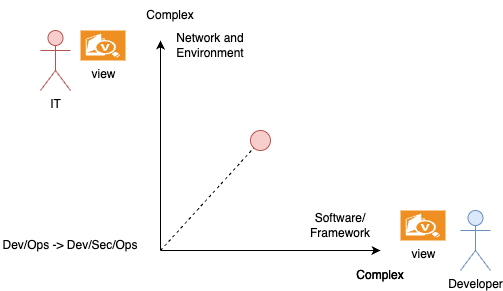
The next image should reflect the newly added complexity to the applications to get into production.
With the introduction of LLMs, a new view, we are introducing new kinds of testing, such as testing prompts outcome which are the most important element for the direct interaction with the model or model frameworks, agent frameworks, data, and tools interacting with models.
With LLM, we can simplify, say, integrating non-deterministic functionality to act on likely deterministic inside applications.
This quote by Klaus Meffert, ‘AI relies on more than just statistics; it uses complex structures like artificial neural networks to understand and process information, similar to how the human brain works’, is particularly relevant in the context of LLMs. It underscores the fact that LLMs, being a form of AI, are not just statistical models but also rely on complex structures like artificial neural networks to process information, that means not always generate the same output.
Currently, a multi-agent application is more like a monolith application with various agents and tools defined for multiple levels of interaction (UI, middleware, data 😉 ) with other AI or traditional applications or services.
There are plans to decouple this monolith using the invention of the Model Context Protocol (MCP) for the tools and the invention of the Agent to Agent (A2A).
This idea results in an operational complexity cube with different views by introducing the third dimension. It is important to notice that not just a single application interacts with a model; often, many applications interact with models or microservices in an entire system. Effective management of these complex, interconnected applications is critical to success.
We should avoid to introduce walls again with the separation of with ML/Ops and Dev/Sec/Ops. We should have the thinking of our systems are from now based on:
Dev/ML/GenAI/Agentic/Sec/Ops
That means, in short we combine deterministic complexity and nondeterministic complexity:
- Deterministic complexity
- Software
- Frameworks
- Nondeterministic (close to 90% correct) complexity
- Model
- Machine Learning
- GenAI
- Model
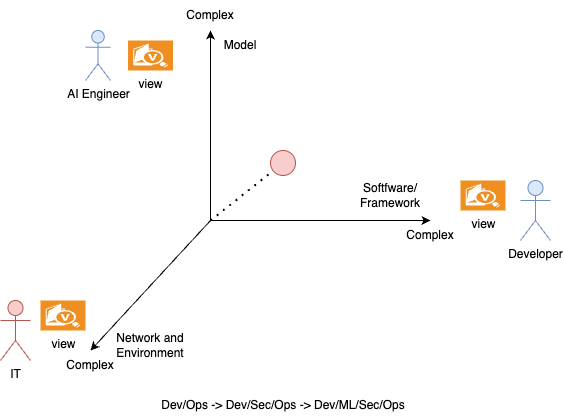
This results in the AI Operational Complexity Cube having different views.
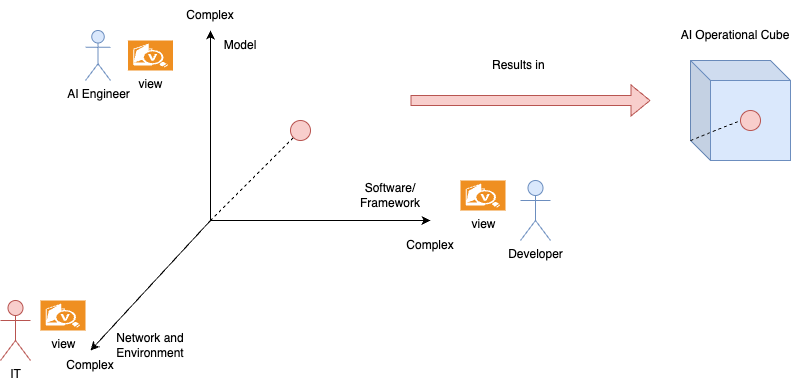
Finally, for example, in a new AI operator role, we want just to see all lights are green 😉

3. Test Large Language Model (LLM) based Applications
With the introduction in mind, let us consider the issues mainly related to LLM-based chat functionalities. To ensure they are robust, reliable, and user-friendly for production, we emphasize the need for comprehensive testing. Having this in mind we can be more sure that we build a quality end product.
The I would say the International Software Testing Qualifications Board ISTQB standards do still apply. The list of topics below results from asking AI how to test AI and using Google search and expand or validated by my personal experience.
1. Define Test Objectives
- Purpose: Clearly outline what you want to test (e.g., conversational flow, accuracy, response time, user satisfaction).
- Metrics: Define success metrics such as response quality, coherence, relevance, and user engagement.
2. Create Diverse Test Cases
- Conversation Types: Understand the different types of conversations (e.g., casual chat, Q&A, task-oriented, troubleshooting) you need to verify.
- Edge Cases: Test with ambiguous, incomplete, or nonsensical inputs to see how the model handles them.
- Multilingual Support: If applicable, test in multiple languages to ensure consistency and accuracy.
3. Use Real-World Scenarios
- User Personas: Understand the application’s stakeholders and users and create conversations with different user personas interacting with the system (e.g., tech-savvy users, beginners, and non-native speakers).
- Domain-Specific Testing: If the LLM is tailored for a specific domain (e.g., healthcare, customer support), test with domain-specific queries.
4. Evaluate Response Quality
- Relevance: Ensure responses are contextually appropriate.
- Accuracy: Verify factual correctness (if applicable).
- Coherence: Check for logical flow and clarity in responses.
- Tone and Style: Ensure the tone aligns with the intended use case (e.g., professional, friendly, formal).
5. Test for Robustness
- Error Handling: Test how the model handles errors, misunderstandings, or offensive inputs.
- Context Retention: Evaluate if the model maintains context over long conversations.
- Fallback Mechanisms: Ensure the model gracefully handles queries it cannot answer.
6. Performance Testing
- Response Time: Measure the time taken to generate responses, especially under high load.
- Scalability: Test the model’s performance with multiple simultaneous users.
7. User Testing
- Beta Testing: Deploy the chatbot to a small group of real users and gather feedback.
- Surveys and Feedback: Use surveys or feedback forms to assess user satisfaction and identify pain points.
8. Automate Testing
- Scripted Conversations: Automated scripts can be implemented to simulate repetitive conversations and measure consistency.
- Regression Testing: Automate tests to ensure new updates or changes do not break existing functionalities.
9. Monitor and Iterate
- Log Analysis: Review conversation logs to identify common issues or areas for improvement.
- Continuous Improvement: Regularly update the model based on feedback and test results.
10. Ethical and Safety Testing
- Bias Detection: Test for biased or inappropriate responses.
- Safety Filters: Ensure the model does not generate harmful, offensive, or misleading content.
- Privacy Compliance: Verify that the model does not inadvertently share sensitive information.
11. Tools and Frameworks
- Testing Frameworks: Use tools like pytest, unittest, or custom frameworks for automated testing.
- A/B Testing: Compare different versions of the model to determine which performs better.
- Analytics Platforms: Track user interactions and engagement with for your applications.
4. Summary
At the end we run applications powered be AI and this at enterprise scale.
So, it makes sense to take a look at how IBM positions Artificial intelligence (AI) solutions and think about how to achieve governance in AI implementation. A good starting point for this can be watsonx.gov for
“End-to-end AI governance is critical for scalability, the toolkit seamlessly integrates with your existing systems to automate and accelerate responsible AI workflows to help save time, reduce costs and comply with regulations”
in combination with IBM Concert
“which is the connective tissue that harmonizes data from disparate tools and environments, transforming it into actionable knowledge aimed at improving operational risk and resiliency and freeing up teams to focus more on innovation“.
This topic will become increasingly important in the future when AI/LLM integration in applications becomes normal mainstream usage, and the operational production lifecycle becomes normal. Also
5. Additional references and resources
- Telecom Datasets: A Closer Look For AI and ML Collection. https://gts.ai/case-study/telecom-datasets-a-closer-look-for-ai-and-ml-collection/
- ISTQB
I hope this was useful to you and let’s see what’s next?
Greetings,
Thomas
#testing, #ai, #complexity, #devops, #devsecops, #aioperationalcomplexitycube, #complexitycube, #llm
