

“RAG is dead” is something you hear more and more often. And in a way, it is true — classic RAG as many people implemented it in 2023 does not scale, does not explain itself, and often breaks in subtle ways.
But RAG itself is not dead. It has evolved, and combinations such as GraphRAG have emerged. My relevant blog post How to Build a Knowledge Graph RAG Agent Locally with Neo4j, LangGraph, and watsonx.ai.
This post is a technical experience report from real work with Retrieval-Augmented Generation systems — built locally, connected to IBM Cloud, using IBM Granite models and Milvus as a vector database. It is not a marketing article, and it is not a hype post. Everything shown here is based on things that actually worked, things that failed, and things that turned out to be more important than expected.
We start from zero and build up step by step: from basic concepts, to ingestion pipelines, to retrieval strategies, to agent-based and multi-tool RAG patterns, all the way to a reproducible, testable end-to-end setup.
Along the way, we explicitly talk about:
- where RAG systems usually break,
- why metadata is more important than most people think,
- how token limits silently destroy retrieval quality,
- and why “just adding an agent” does not magically fix bad retrieval.
The title “RAG Is Dead … Long Live RAG” reflects this journey. RAG 1.0 — simple retrieve-and-summarize pipelines — is no longer sufficient. What replaces it is a more deliberate, structured, and observable approach: optimized queries, multiple retrieval modes, tools, agents, and strong emphasis on reproducibility and debugging.
If you are looking for a copy-paste tutorial, this post is not for you. If you want to understand why modern RAG systems behave the way they do, how to design them cleanly, and how to avoid common traps, then this guide is written exactly for that purpose.
TABLE OF CONTENTS
PART I — Foundations
- What This Post Is About
- Why “RAG Is Dead … Long Live RAG”
- Core Concepts (LLMs, Embeddings, Vector DBs, RAG 1.0 → RAG 2.0)
- IBM Granite Models Overview
- Local vs. Cloud Execution Model (Our Architecture)
PART II — Starting From Zero
- Setting Up Your Environment (Local + IBM Cloud)
- Preparing Your Data
- Preprocessing & Chunking
- Metadata Strategy (Critical!)
PART III — Building Retrieval
- Milvus Collections, Indexes & Search Types Explained
- Ensuring Embedding Dimensions Always Match
- Query Optimization (Pre-Analysis Prompting)
- Token Length Effects & How To Fix Them
PART IV — The 7 RAG Invocation Patterns (Options)
- Pure Vector Search
- Retrieve + Summarize (One Prompt)
- Agent-Based RAG (Interactive)
- Optimized Query + One-Prompt RAG
- Optimized Query + Agent RAG
- Multi-Tool RAG (Vector Search + Summaries + Optimizers)
- Full Hybrid Mode (Everything Combined)
PART V — Putting It All Together
- Building a Reproducible RAG Test Framework
- Storing Metadata for Full Traceability
- Replay Mode (Deterministic RAG)
- Logging, Evaluation & Debugging
PART VI — Full Local Python + IBM Cloud Implementation
- Local Environment (Python)
- Using IBM Granite Embedding Models (Cloud inferencing)
- Milvus Cloud Setup (IBM Cloud Deployment)
- Local End-to-End RAG Pipeline (All 7 Modes Implemented)
- GitHub Ready Project Structure
- References, Transparency Notes & Legal Considerations
PART I — FOUNDATIONS
1.1. What This Post Is About
This post is your Zero-to-Hero guide for building modern Retrieval-Augmented Generation (RAG) systems using:
- IBM Granite models on IBM Cloud
- Milvus (watsonx.data on IBM Cloud hosted)
- Local Python runtime (your laptop / local server)
This post provides you with a guide :
- IBM Granite Models
- Milvus Vector Database on IBM Cloud
- Local development
- Transparent, reproducible pipelines
- Test frameworks
- Agent-based multi-step RAG
and contains:
- fundamentals
- architecture
- code
- debugging
- reproducibility
- test frameworks
- advanced RAG patterns
Everything in one place. No searching for internet fragments. Hopefully, “no missing pieces.”.
1.2. Why “RAG Is Dead … Long Live RAG”
Retrieval-Augmented Generation is not dead.
1.2.1. Challenge still exists
Large Language Models have three hard limits:
- They forget (without a framework)
- They hallucinate
- They do not know your private data
No matter how big the model is:
- It does not know your PDF
- It does not know your database
- It does not know your tickets, logs, or emails
RAG solves exactly this:
“Bring your knowledge to the model at runtime.”
1.2.2. Confusion
Every few months, a new headline appears:
- “RAG is dead”
- “Agents replace RAG”
- “Fine-tuning beats retrieval”
- “Just use context windows”
And every time, the same thing happens:
Sometimes people confuse tools with architecture.
RAG is not a product. RAG is not a framework. RAG is not a model.
1.2.3. A Pattern
RAG is a pattern. A pattern that simply means:
“Before the LLM answers, it retrieves knowledge from somewhere else.”
That is all.
But the old way of doing RAG is definitely dead. Smart RAG replaced it.
Traditional RAG (“RAG 1.0”) looked like this:
User Question → Embedding → Vector Search → LLM Summarizes → Answer
Modern RAG is more like this:
Pre-Analysis → Query Optimization → Retrieval → Reranking → Reasoning → Tools → Final Answer
1.2.4. Traditional RAG Overview
The following images display the basic architecture. We start with traditional RAG. Figure 1 shows the complete end-to-end RAG process, including offline indexing and query-time retrieval. This separation is the foundation of everything discussed in the rest of this post.

Figure 1
The figure 2 displays the RAG Ingestion Pipeline and retrieval.

Figure 2
The figure 3 shows an example of multiple LLM interactions
FYI: A RAPTOR retriever adds hierarchical, LLM-generated summaries to your vector index so that a RAG system can retrieve information at the right level of abstraction, not just the closest chunk.
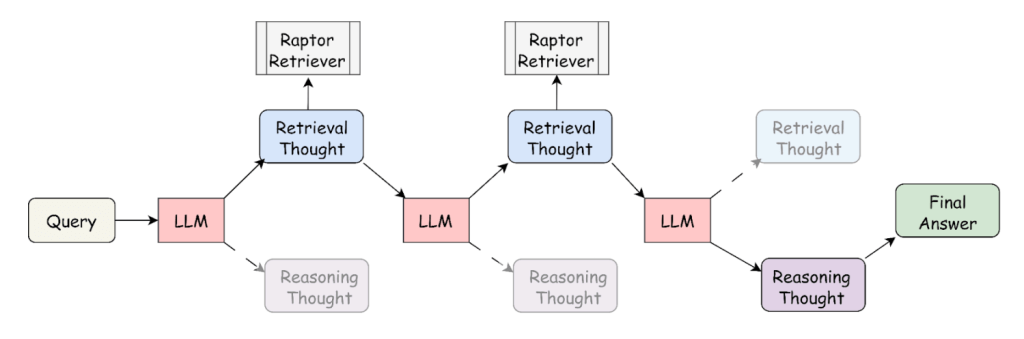
Figure 3
1.3. Core Concepts and Termologies
LLM→ Large language model (IBM Granite in our case).- The LLM is the reasoning engine.It does NOT:
- Search
- Retrieve
- Remember
- Reads what you give it
- Produces an answer
- The LLM is the reasoning engine.It does NOT:
Embedding→ Turns text into numerical vector.- Embeddings are numbers that represent meaning.
Example:
“What is RAG?”
→ [0.0123, -0.9912, 0.4421, …] - Key rules:
- Same meaning → similar numbers
- Different meaning → far away numbers
- The vector size is fixed
- The text length does NOT change that size
- This is the bridge between:
- Human language
- Machine search
- Embeddings are numbers that represent meaning.
Vector DB→ Stores embeddings, performs similarity search.- A vector database stores:
- Embeddings
- Metadata
- Chunk text
- Similarity searchFilteringRankingHybrid retrieval
- Milvus
- Elastic (vector mode)
- Weaviate
- PGVector
- A vector database stores:
Chunk→ Small piece of document.Metadata→ Information about each chunk (VERY IMPORTANT).RAG→Retrieve→Augment→Generate
Note: All of these concepts appear together in the full RAG shown in
Figure 1.
1.4. IBM Granite Models Overview
IBM Granite (2024+) includes:
- Embedding Models
- Granite Embedding 30B
- Granite Code Embeddings
- Granite Multilingual Embeddings
LLMs
- Granite 13B
- Granite 34B
- Granite 70B (Cloud)
1.5. Architecture: IBM Cloud + watsonx + Local
- Extraction, Preprocessing and ingestion

Figure 4
- Retrieval with a local tool implemented in as a REST API or MCP server.

Figure 5
- Retrieval with an agent and tool implemented as a REST API or MCP server. The Tools Server running in IBM Cloud Code Engine can also run locally as a container or application. (watsonx Orchestrate, watsonx.ai, watsonx.data, Code Engine )

Figure 6
Choice for the implementation:
- Local Code Execution
- watson.ai IBM Granite Models
- Milvus Vector DB in watsonx.data on IBM Cloud
1. Local will handle:
- preprocessing
- chunking
- ingestion
- query optimization
- agent orchestration
- testing
- reproducibility
2. Cloud will handle:
- embedding generation
- LLM generation
- vector search
- data storage
PART II — STARTING FROM ZERO
All following code snippets are illustrative and focus on structure and integration, not production-ready execution.
2.1. Setting Up Your Environment
This is how we can organize a folder structure for an example project. (Local Python + IBM Cloud)
Folders:
rag-structure/
├── src/
│ ├── embeddings.py
│ ├── vectorstore.py
│ ├── rag_modes.py
│ ├── agent.py
│ ├── utils.py
│ └── replay.py
├── data/
├── configs/
├── tests/
└── README.md
2.2. Preparing Your Data
You should never ingest raw documents.
Data preparation includes:
- Extract text
- Remove tables, signatures, junk
- Normalize whitespace
- Fix unicode issues
- Detect language
2.3. Preprocessing & Chunking
Chunking rules:
~300–600tokens usually best- Overlap of
10–20% - Chunk boundaries must respect semantic units
2.4. Metadata Strategy
Metadata is the SINGLE most important part of modern RAG. Every chunk should include:
- source_name
- source_type
- timestamp
- author
- heading
- paragraph index
- tags
- keywords
- embedding model version
- chunking version
2.5. Ensure you have your Ground Truth ready
In almost every RAG project we worked on, the hardest part was not the model, not the vector database, and not the framework. The real challenge was always the same. You can skip this chapter, because it is a bit one.
2.5.1 What is our ground truth?
If you take only one thing from this chapter, it should be this:
A RAG system is only as good as its golden data: the golden questions, the golden answers, and the documents that justify them.
This problem did not disappear with better models. In fact, it became more visible.

Figure 7
My blog post Land of Confusion using Classifications, and Metrics for a nonspecific Ground Truth is related to this topic.
2.5.2 What We Mean by Ground Truth in RAG
In classical machine learning, ground truth usually means labeled data. In RAG, ground truth is more subtle and consists of three tightly connected parts:
- Golden Questions
- Golden Answers
- Golden Data (Source Documents)
They must be consistent with each other. If one part is weak, the entire system becomes unreliable.
2.5.3 Golden Questions
Golden questions define what the system must be able to answer.
Good golden questions are:
- Realistic (asked by real users or domain experts)
- Unambiguous
- Grounded in the available data
- Stable over time (or at least versioned)
Bad golden questions are:
- Vague or underspecified
- Hypothetical questions without supporting documents
- Questions that require reasoning beyond the data you actually store
In practice, we learned that collecting golden questions is a business activity, not a technical one. Engineers can help structure them, but domain experts must define them.
2.5.4 Golden Answers
Golden answers are not just “the correct text”.
A good golden answer:
- Is factually correct
- Is aligned with the business domain language
- Can be justified by specific documents
- Is scoped (not overly verbose, not overly short)
This is where many RAG evaluations fail. If your golden answer is vague or poorly written, you cannot reliably judge the system output later.
We strongly recommend storing:
- The golden answer text
- Metadata (version, author, date)
- References to the supporting documents
Golden data answers a simple but uncomfortable question:
2.5.5 Which documents are allowed to be used to answer this question?
For each golden question, you should ideally know:
- Which documents must be retrieved
- Which documents must not be retrieved
- Which document passages are actually relevant
This is critical because many RAG systems fail silently: They produce a good-looking answer based on the wrong sources.
If you do not check document correctness, you are testing text generation, not retrieval.
2.5.6 Why This Is Still the Hardest Problem
Even with better embeddings, larger context windows, and agents, the problem remains:
- Data changes
- Policies change
- Documentation quality varies
- Business language evolves
There is no “one-size-fits-all” solution here. Ground truth must be treated as a living asset, not as a static test dataset.
2.5.7 Synthetic Data Generation (With Care)
To scale evaluation, we often add synthetic data generation.
Typical use cases:
- Generate paraphrases of golden questions
- Generate variations with different wording
- Generate negative examples (questions that should not match)
This helps with coverage, but it comes with risks.
Synthetic data is useful for:
- Stress testing retrieval
- Improving robustness
- Detecting embedding weaknesses
Synthetic data is not a replacement for real golden questions.
Our rule of thumb:
Synthetic data may extend ground truth, but it must never define it.
2.5.8 Model as a Judge (Instead of Confusion Matrices or other metrics for AI quality)
In older systems, we relied heavily on confusion matrices: precision, recall, F1, accuracy.
In RAG, this often breaks down.
Why?
- Answers are not binary
- Partial correctness matters
- Language quality matters
- Source correctness matters
Today, a more practical approach is model-as-a-judge.
Typical evaluation dimensions include:
- Is the answer correct?
- Is the answer grounded in the retrieved documents?
- Are the correct documents used?
- Is the answer complete and not hallucinated?
A strong LLM, prompted carefully, can evaluate these dimensions far better than traditional metrics.
Important: The judge model must be separate from the generation model to avoid bias.
2.5.9 Validation, Not Illusion of Precision
Model-as-a-judge does not give you a single “accuracy number”. And that is a good thing.
Instead, you get:
- Structured feedback
- Qualitative explanations
- Actionable signals for improvement
This shifts evaluation from false precision to practical validation. My blog post Land of Confusion using Classifications, and Metrics for a nonspecific Ground Truth is related to this topic.
2.5.10 Key Takeaways
- Ground truth in RAG means golden questions, answers, and data — together
- Data quality is still the dominant success factor
- Synthetic data helps, but only as an extension
- Model-as-a-judge is more useful than confusion matrices
- Evaluation must focus on correctness and grounding
In the end, RAG is not primarily a modeling problem. It is a data and validation problem — and it will remain one for the foreseeable future.
PART III — BUILDING RETRIEVAL
3.1. Milvus Collections, Indexes & Search Types
The figure 7 displays the basic dependencies in Milvus for more details please visit the Milvus documentation

Figure 8
- Field Schema
vector_embedding = FieldSchema(
name="vector_embedding",
dtype=DataType.FLOAT_VECTOR,
dim=1024
)
- Index Types
- HNSW → fast, accurate
- IVF_FLAT → scalable
- FLAT → exact
- Search Metrics
- COSINE (recommended)
- IP
- L2
- Example Search Source Code
search_vector_embedding = embed_text(search_text)
res = self.client.search(
collection_name=collection_name,
anns_field="vector_embedding",
data=[search_vector_embedding],
limit=self.search_limit,
search_params={"metric_type": "COSINE"}
)
3.2. Ensuring Embedding Token Size And Dimension Always Matches
Embedding size is fixed per model.
Example: Granite Embedding Model → 1024 dims As long as documents and questions use SAME MODEL, dimensions always match.
3.3. Query Optimization
Critical for modern RAG. The query optimization is very important because today with the huge context input sizes so the question and the related information can be much longer than the allowed tokensize for the embedding, this is the reason why the next chapter is so important. We need to take care about the token length and dimensions.
Prompt:
Rewrite the question to be short, unambiguous, and optimized for embedding-based vector retrieval.
Keep only the semantic core.
3.4. Token Length Effects
Long questions → semantic dilution. Fix:
- rewrite
- extract core meaning
- remove story details
- reduce noise
PART IV — 7 RAG PATTERNS
Basic overview.
- Basic RAG usage in combination with other data resources and an inference platform.

Figure 9
- Retrieval Agent
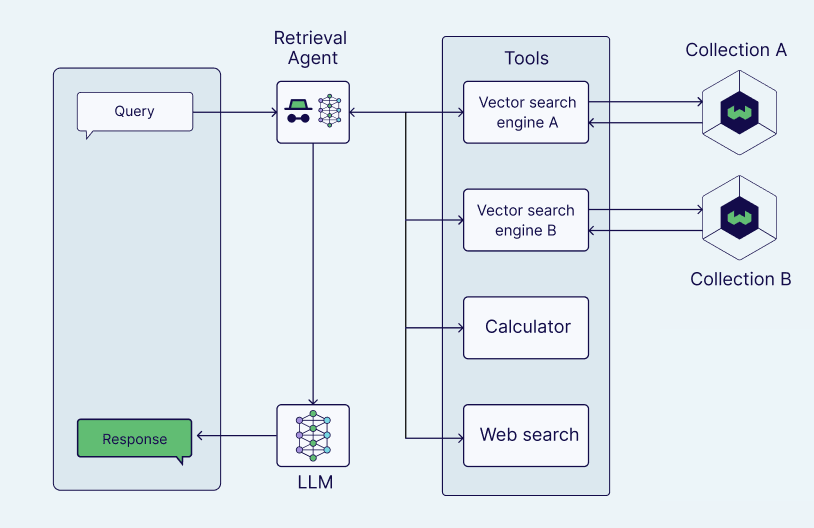
Figure 10
- Retrieval Agent Outline Options

Figure 11
- RAG configuration options:
- 1. Pure Vector Search The simplest setup, focusing only on semantic similarity search over embeddings. It is fast and easy to operate, but relies heavily on high-quality chunking and embeddings, with no reasoning or synthesis step.
- 2. Classic RAG (Retrieve + Summarize Once) Documents are retrieved once and summarized in a single LLM prompt. This pattern is widely used, easy to understand, and sufficient for many use cases, but limited when questions require decomposition or deeper reasoning.
- 3. Agent RAG An agent controls retrieval and reasoning across multiple steps. This enables iterative querying, decision-making, and adaptive behavior, but increases complexity, cost, and the need for strong observability and guardrails.
- 4. Optimized Query + Single Prompt The user query is rewritten or enriched before retrieval, then answered in one prompt. This improves recall and relevance while keeping the architecture simple and predictable and testable.
- 5. Optimized Query + Agent Query optimization is combined with an agent-based execution flow. This approach balances better retrieval quality with flexible reasoning, but requires careful tuning to avoid unnecessary agent loops.
- 6. Multi-Tool RAG The RAG system can invoke multiple tools such as vector search, SQL, APIs, or domain services. This is the most powerful pattern, but also the most demanding in terms of data quality, ground truth, and operational discipline.
- 7. Full Hybrid Mode (Everything Combined)
- You expose:
- Query rewrite tool Transforms the user input into a clearer, more retrievable query. This step improves recall and reduces ambiguity, especially for short or underspecified questions. For example doing a preanalysis of context of a question.
- Retrieval tool Encapsulates access to vector stores, hybrid search, or structured backends. Its quality is primarily determined by data preparation, chunking strategy, and metadata design.
- Summarization tool Condenses retrieved content into a focused context for the LLM. This helps control token usage and reduces noise, but can hide missing or weak source data.
- Agent with tool-selection logic Decides which tools to call and in which order based on the task. This enables flexible reasoning and orchestration, but shifts complexity from prompts to system design and evaluation.
PART VI — FULL IMPLEMENTATION
4.1. ARCHITECTURE IMPLEMENTATION
4.1.1. Retrieval Augmented Generation

Figure 12
4.2. Local Python Environment
python-milvus
ibm-watsonx-ai
pydantic
fastapi
4.3. Example using IBM Granite Embeddings in watsonx.ai on IBM Cloud
from ibm_watsonx_ai.foundation_models import Model
from ibm_watsonx_ai.foundation_models import Embeddings
from ibm_watsonx_ai import Credentials
from ibm_watsonx_ai.metanames import EmbedTextParamsMetaNames as EmbedParams
embed_params = {
EmbedParams.TRUNCATE_INPUT_TOKENS: int(os.getenv("WATSONX_EMBEDDING_MODEL_TRUNCATE_INPUT_TOKENS")),
EmbedParams.RETURN_OPTIONS: {
'input_text': True
}
}
granite_embed = Model(
model_id="ibm/granite-embedding-30b",
credentials=creds,
params=embed_params,
project_id=self.project_id
)
def embed_text(text):
res = granite_embed.embed(text)
return res['vector'] # 1024 dims
4.4. Milvus watsonx.data (IBM Cloud)
Generate a Milvus client.
from pymilvus import MilvusClient
client = MilvusClient(uri=os.getenv('MILVUS_URI'),
user=os.getenv('MILVUS_USER'),
password=os.getenv('MILVUS_APIKEY'),
database=os.getenv('MILVUS_DB_NAME'))
4.5 Use a prompt template on watsonx.ai in a watsonx.ai deployment
You can use a watsonx.ai prompt template deployed on watsonx.ai to generate the summary. Also useful in this context is the blog post AI Prompt Engineering: Streamlining Automation for Large Language Models.
token = f"Bearer {self._get_bearer_token()}"
header = {"Content-Type": "application/json", "Authorization": token }
url = f"https://{self.watsonx_config['WATSONX_REGION']}.ml.cloud.ibm.com/ml/v1/deployments/{self.watsonx_config['WATSONX_DEPLOYMENT_ID']}/text/generation?version=2021-05-01"
timer0 = time.time()
try:
response_error_analysis = requests.post(
url,
data= json.dumps(payload_prompt_template),
verify= False,
headers= header,
)
4.6 Use an agent in watsonx Orchestrate (locally or remote)
In this context it is useful to understand the watsonx Orchestrate REST API an easy starting point can be my blog post REST API Usage with the watsonx Orchestrate Developer Edition locally: An Example.
def chat_completion(self, question:str, rag_summany: str):
agent_id = self.watsonx_config['WATSONX_ORCHESTRATE_AGENT_ID']
base_url = self.watsonx_config['WATSONX_ORCHESTRATE_BASE_URL']
endpoint = f"v1/orchestrate/{agent_id}/chat/completions"
self.agent_url = f"{base_url}/{endpoint}"
token = self._get_bearer_token()
content = f"Question:\n{question}\nRAG summary:\n{rag_summany}\n"
payload = { "messages": [
{
"role": "human",
"content": content
}
],
"additional_parameters": {},
"context": {},
"stream": False
}
headers = {
"Authorization": f"Bearer {token}",
"Content-Type": "application/json"
}
# Invoke the agent in watsonx Orchestrate
try:
response = requests.request("POST",
self.agent_url,
json=payload,
headers=headers)
if response.status_code == 200:
return response_agent
else:
return response
except Exception as e:
response = f"Exception:\n{e}"
return response
4.6. Full Local RAG Pipeline (All Options)
def rag_pipeline(question, option):
q_opt = optimize_question(question)
q_emb = embed_text(q_opt)
hits = milvus_search(q_emb)
if option == 1:
return hits
if option == 2:
return llm_summarize(question, hits)
if option == 3:
return agent_process(question, hits)
4.7 Potential github repository structure
rag-zero-to-hero/
├── src/
│ ├── embeddings.py
│ ├── vectorstore.py
│ ├── rag_options.py
│ ├── agent.py
│ ├── optimizers.py
│ ├── config.py
│ ├── replay.py
│ ├── evaluation.py
│ └── main.py
├── configs/
├── tests/
├── data/
├── docs/
├── README.md
└── LICENSE
5. Summary
With this post, I am not trying to define the perfect RAG architecture or claim that it will still look the same tomorrow. The reality is that everything around RAG changes extremely fast: APIs, frameworks, programming models, agents, tools, and even the way we think about large language models. What is relevant today may be obsolete in a few months.
The goal of this post is therefore different. I want to create something as close as possible to a “one-size-fits-most” foundation for Retrieval-Augmented Generation as it is relevant today. A single reference point that brings together the essential concepts, patterns, and architectural decisions that consistently matter across projects — regardless of which specific framework, SDK, or model happens to be fashionable at the moment.
This post is meant to ensure that the basics are truly understood: what RAG actually is (and is not), where it breaks, why naïve implementations fail, and which design choices have long-term impact. It deliberately focuses on fundamentals such as data preparation, chunking, metadata, embeddings, retrieval strategies, token limits, observability, and reproducibility — because these aspects remain stable even as tooling evolves.
The examples in this post use IBM technologies (IBM Granite models, watsonx.ai, watsonx.data, Milvus, and watsonx Orchestrate) for a simple reason: this is the ecosystem I know best and have used extensively in real projects. The architectural patterns and lessons, however, are not IBM-specific and can be transferred to other platforms with minimal adaptation.
Across multiple RAG projects, one challenge has consistently dominated all others: data quality and ground truth. Not models, not agents, not vector databases — but the availability of reliable source data, well-defined questions, and trustworthy answers. Even with emerging approaches such as synthetic data generation or “model-as-a-judge” evaluation, this problem does not disappear. It merely changes shape, and it will remain a central challenge for the foreseeable future.
This post is therefore not a promise of future-proof solutions. It is a consolidation of hard-earned lessons from real RAG systems, intended to give readers a stable mental model and a solid starting point — so that when the next framework, API, or agent abstraction appears, they can evaluate it with clarity instead of starting from zero again.
I hope this was useful to you and let’s see what’s next?
Greetings,
Thomas
FYI: References, Transparency Notes & Legal Considerations for this post
This article is based on my own practical experience with Retrieval-Augmented Generation systems. I used AI tools selectively to help structure and refine the text. All technical content, architectural decisions, and conclusions reflect my own understanding and judgment.
#RAG, #Retrieval-AugmentedGeneration, #RAGArchitecture, #LargeLanguageModels, #VectorSearch, #AgenticAI, #Query Optimization, #GroundTruthData, #GoldenData, #SyntheticDataGeneration, #ModelAsAJudge, #AISystemDesign, #Enterprise AI, #IBMwatsonx
