
Infrastructure as Code and GitOps are ongoing big topics related to DevOps and CI/CD which needs effective automation to shorter the Software Development Lifecycle and simplify production deployments.
In this blog post we don’t talk much about these processes and methodologies. The blog post is more about how to reduce efforts to build an automation by using the IBM Accelerator Toolkit.
In the Automation for IBM Watson Deployments project we see how easy it is to use a fully automated way for a setup of an infrastructure and the deployment of a Watson NLP library application. The project uses the IBM Accelerator Toolkit to combine Infrastructure as Code and GitOps automation.
Watson NLP is a part of the embedded AI solution for IBM Partners to “close the skills gap and reduce development time to create trustworthy AI-powered solutions“.
The blog post is structured in following sections:
- The IBM Accelerator Tool Kit framework for the automation
- The Automated Setup
- Additional information
- Summary
The IBM Accelerator Toolkit framework for the automation
With the IBM Accelerator Toolkit we can combine the automation of Infrastructure as Code and GitOps.
The IBM Accelerator Toolkit “is an opinionated open source framework on top of the standard technologies Terraform and ArgoCD. The toolkit allows automating deployments and operations of infrastructure like Red Hat OpenShift clusters and applications”. With all this in mind we see that this framework combines the power of automation for Infrastructure as Code with Terraform and for GitOps it uses ArgoCD.

Note: The image above is related to the blog post Introducing IBM’s Toolkit to handle Everything as Code.
The GitHub project called Automation for IBM Watson Deployments uses the IBM Accelerator Toolkit.
The Automation for IBM Watson Deployments project uses existing Terraform and GitOps modules of the framework which are available in the public module catalog. The modules are used to configure a Bill of Material BOM configuration. This configuration is used as an input for a CLI tool called iascable (Infrastructure as code capable) that is a part of the framework. This tool creates the needed Terraform code which will be executed to automate the setup with Terraform. The code will create all the resources in the IBM Cloud or in other cloud providers and it installs and configures ArgoCD to deploy the application.

The image above shows the Watson NLP module entry in the public module catalog.
Simplified we can say: A BOM defines what you want to setup or configure. You use in the BOM all the modules you need to create the Terraform code to automate the creation or the configuration you plan to do.
With that approach you don’t need to know how to write Terraform code in detail or how to write ArgoCD yaml configurations. Surely you need a basic understanding how ArgoCD and Terraform works, but the entire setup is done for you with no need to code.
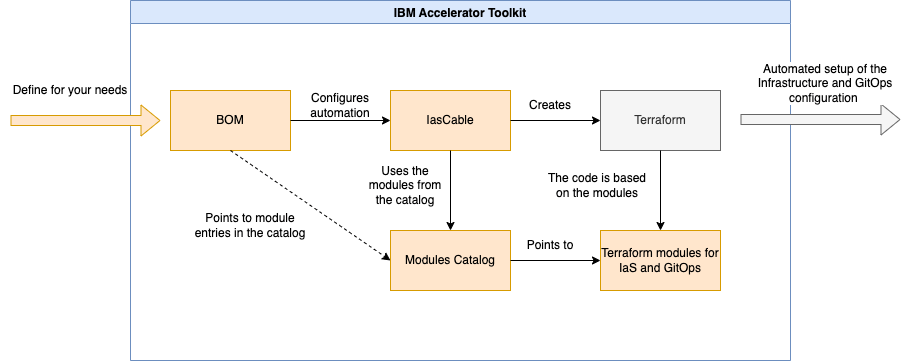
The diagram above shows the high level dependencies.
The automated setup
The project Automation for IBM Watson Deployments project provides you a guided way how to use the framework for an automated setup. Please visit the Automation for IBM Watson Deployments project for the detailed steps of the setup.
The IBM Accelerator Toolkit fully automates the configuration and the setup of the infrastructure and Watson NLP on OpenShift.
Let’s have a more detailed look at the automation used in Automation for IBM Watson Deployments project.
The automation …
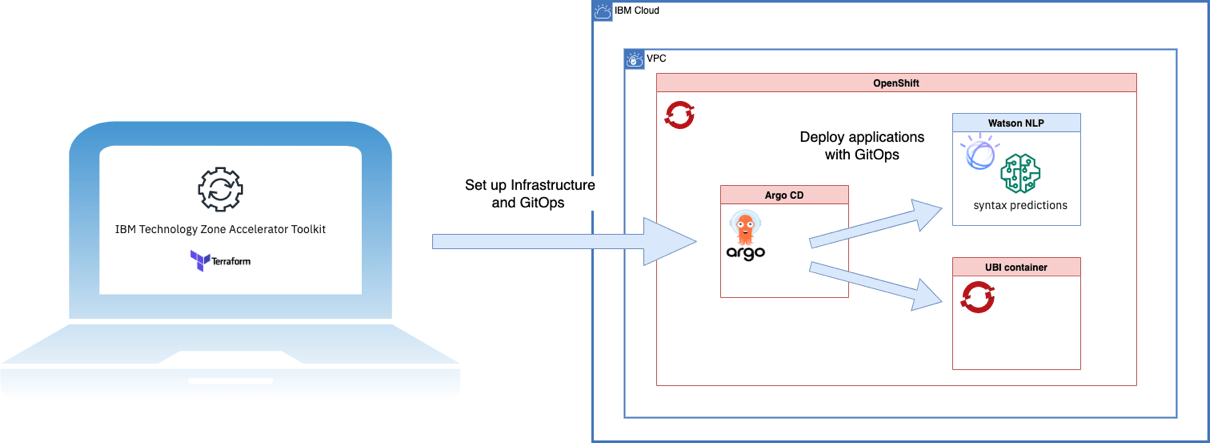
… creates a managed OpenShift cluster on the IBM Cloud in a VPC.
… creates and configures an ArgoCD on the OpenShift cluster.
… deploys with GitOps the Watson NLP application, which consists of two elements:
a) the runtime providing gRPC and REST interfaces
b) a model for syntax predictions
… creates a consumer example “Red Hat Universal Base Image” container which is configured to run a command that invokes the Watson NLP via REST.

The image above shows simplified the automated creation of the various resources with the IBM Accelerator Toolkit.
The verification
After the deployment of the Watson NLP library application, we can invoke the REST API of Watson NLP .
For more details please visit the Automation for IBM Watson Deployments project.
The gif below shows the end-to-end example of the setup including the simple verification.
- Create the infrastructure and setup GitOps
- Deploy the applications
- Verify the deployed application

Additional information
I wrote some blog posts about the IBM Accelerator Toolkit framework before, at that time is was called Software Everywhere, maybe these blog posts are useful for you. These blog posts are likely a kind of a little learning journey around the basic usage.
- GET STARTED WITH AN INSTALLABLE COMPONENT INFRASTRUCTURE BY SELECTING COMPONENTS FROM A CATALOG OF AVAILABLE MODULES WITH IASCABLE
- USE IASCABLE TO CREATE A VIRTUAL PRIVATE CLOUD AND A RED HAT OPENSHIFT CLUSTER ON IBM CLOUD
- USE SOFTWARE EVERYWHERE AND IASCABLE TO SETUP GITOPS ON A RED HAT OPENSHIFT CLUSTER IN A VIRTUAL PRIVATE CLOUD ON IBM CLOUD
You can get more additional detailed of the IBM Accelerator Toolkit information in the evolving Operate documentation.
Summary
I am still impressed how powerful the IBM Accelerator Tool Kit is and how it combines Infrastructure as Code and GitOps to simplify automation, so that the need of knowledge for Terraform and ArgoCD can be reduced to a minimum. The IBM Accelerator Toolkit is continued. Please visit the Automation for IBM Watson Deployments project for the detailed steps of the setup.
I hope this was useful to you and let’s see what’s next?
Greetings,
Thomas
#ibmcloud, #openshift, #terraform, #cloudnativetoolkit, #softwareeverywhere, #iascable, #gitops, #IBMAcceleratorToolkit, #watsonnlp
