

If you want to check out the Watson Natural Language Processing service only, you can get a free trial on IBM Cloud.
This blog post is about using the new IBM Watson Natural Language Processing Library for Embed on your local computer with Docker.
The IBM Watson Libraries for Embed are made for IBM Business Partners. Partners can get additional details about embeddable AI on the IBM Partner World page. If you are an IBM Business Partner you can get a free access to the IBM Watson Natural Language Processing Library for Embed.
To get started with the libraries you can use the link Watson Natural Language Processing Library for Embed home. It is an awesome documentation and it is public available.
I used parts of the great content of the IBM Watson documentation for my Docker example. I created a GitHub project with some additional example bash scripting. The project is called Run Watson NLP for Embed on your local computer with Docker.
The blog post is structured in:
- Some simplified technical basics about IBM Watson Libraries for Embed
- Some screen shots from a running example using Docker
- Inspect the runtime container image
- Execute the example locally
- Summary
1. Some simplified technical basics about IBM Watson Libraries for Embed
The IBM Watson Libraries for Embed do provide a lot of pre-trained models you can find in the related model catalog for the Watson Libraries. Here is a link to the model catalog for Watson NLP, the catalog is public available.
There are runtime containers for the AI functionalities like NLP, Speech to Text and so on. You can integrate the container into your application and customize them, for example existing pre-trained models, but it’s also possible to use own created models. By separating the container runtime and the models to be loaded into the container, we are free to include the right models we need to integrate in our application to fulfil the needs of our business use case.
The resources are available in a IBM Cloud Container Registry. The image below shows a simplified overview.

The next gif shows a simplified overview of the dependencies and steps we need to execute when we using Docker to run the runtime container on our local machine. You can find the detailed instructions in the official IBM documentation installing running containers.
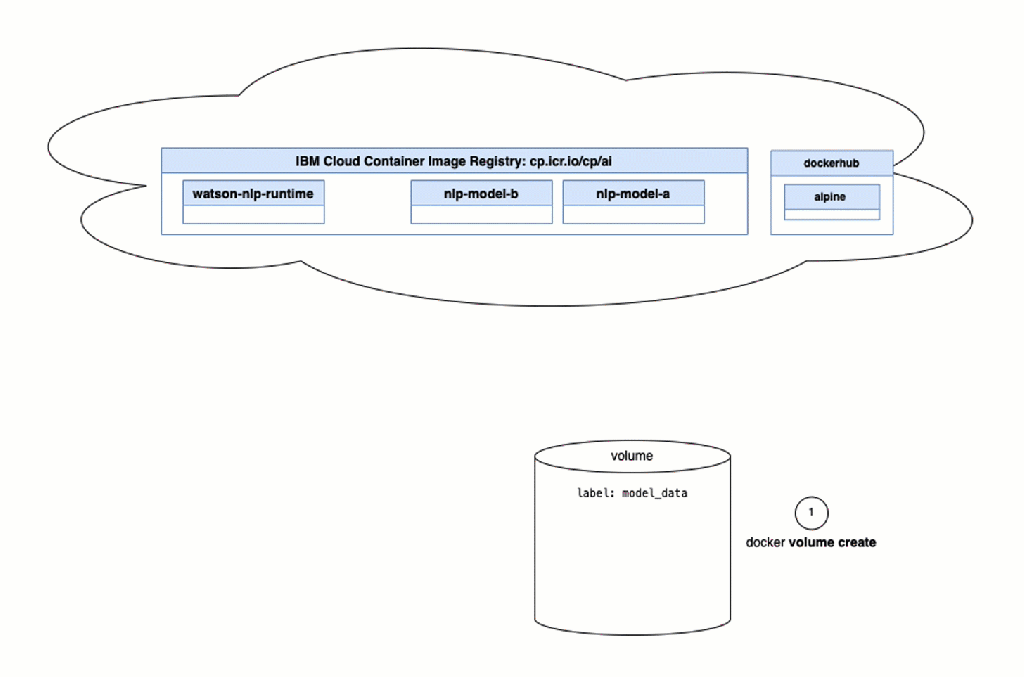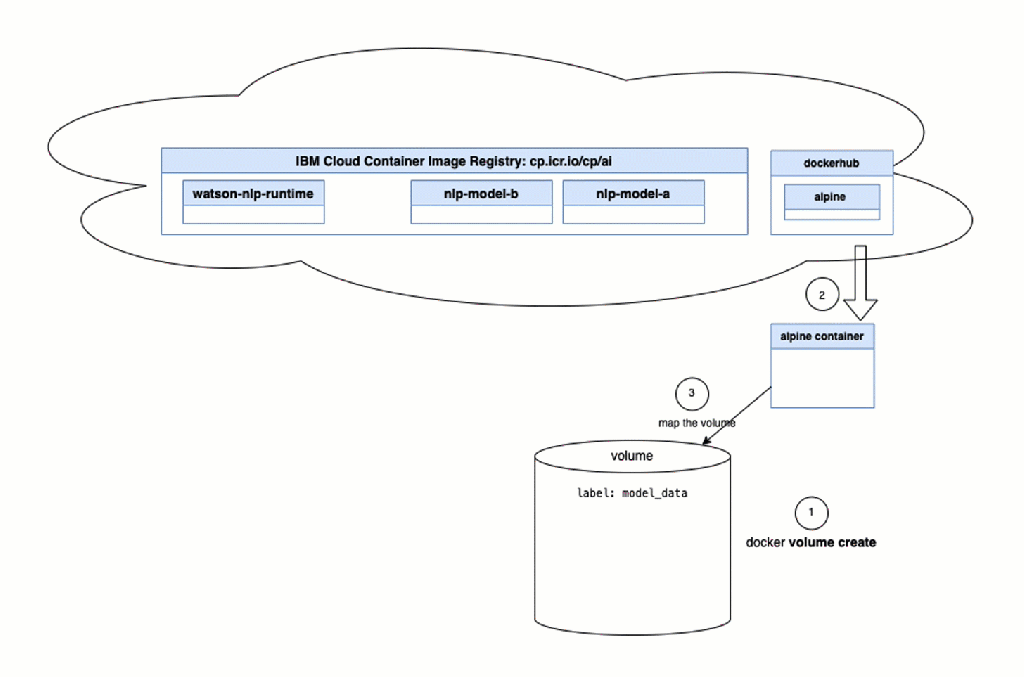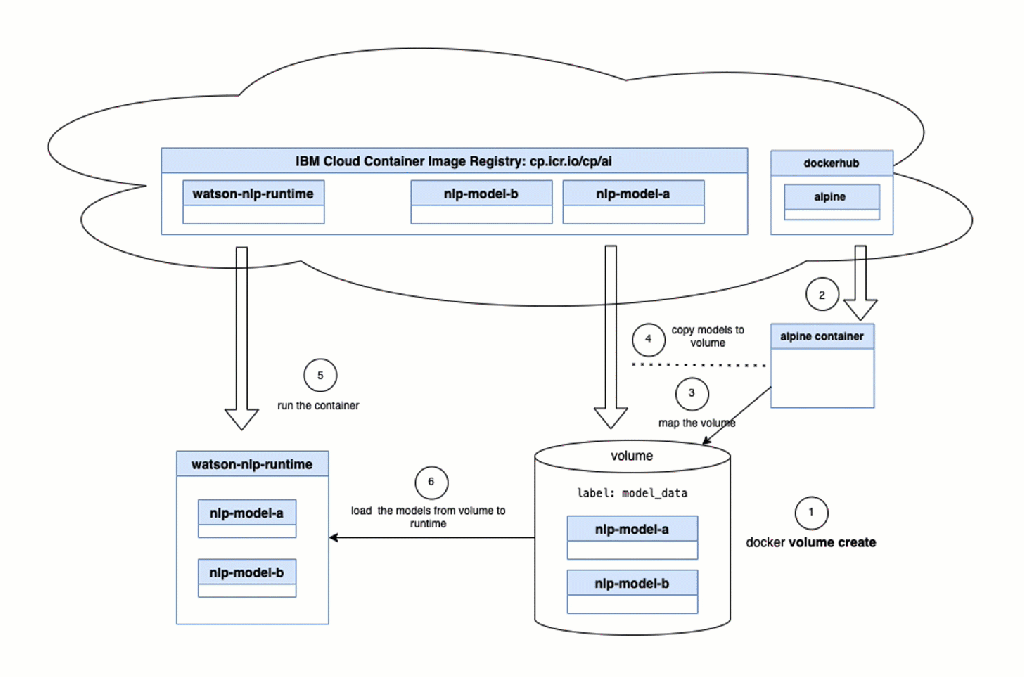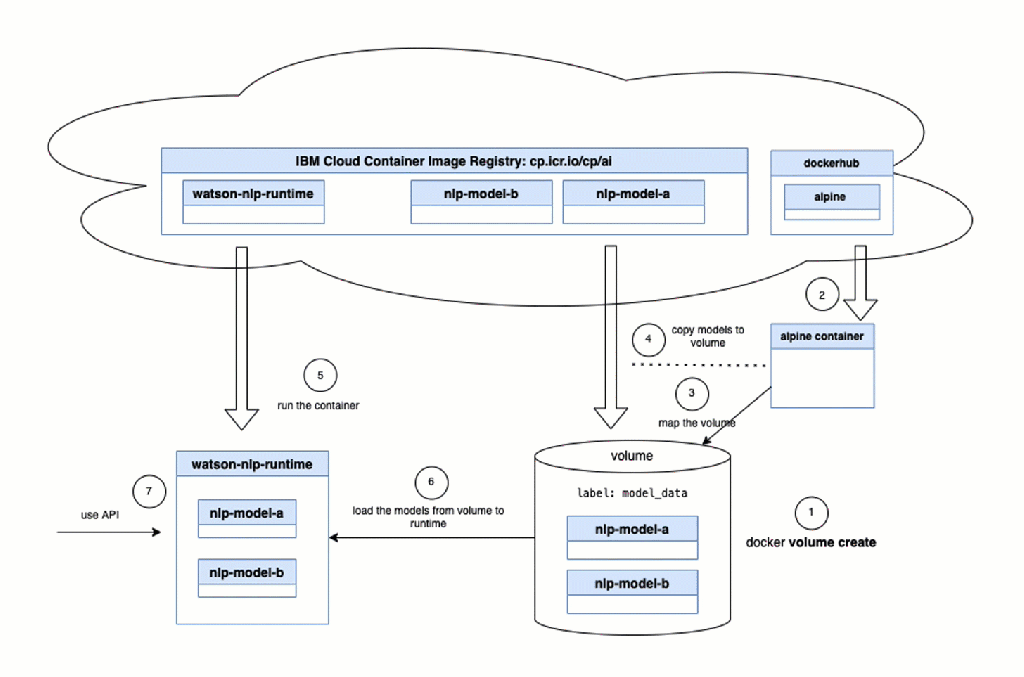
These steps are automated steps in the bash script automation, we see in the image above.
- Create a Docker volume for the models
- Run an Alpine image container.
- Alpine container: Map the volume for the models
- Alpine container: Copy the models to the volume
- Run the Watson NLP runtime container and map the volume to the container.
- Watson NLP runtime container: Load the models from the mapped volume
- Watson NLP runtime container: Ready to go!
2. Some screen shots from a running example using Docker
- The Docker volumes:
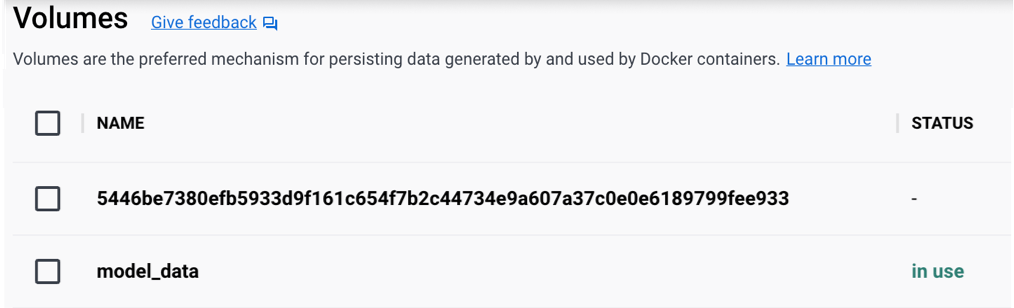
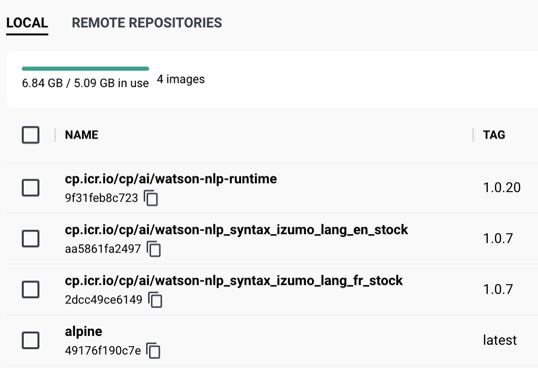
- The image below shows the downloaded images:
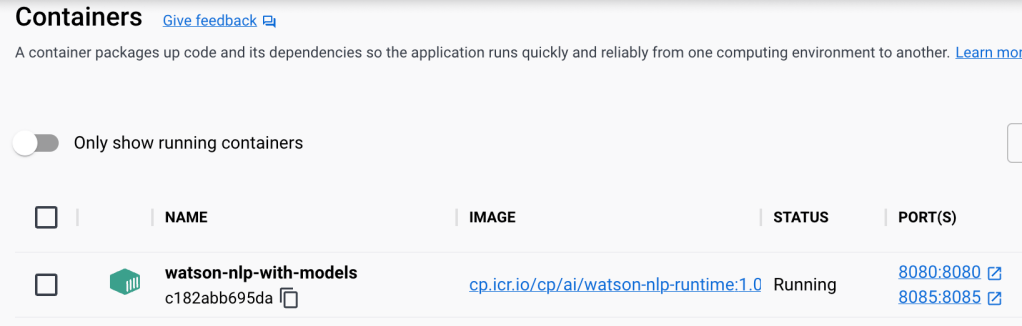
- The runtime container:
Inspect the runtime container image
With docker inspect we get the details of the watson-nlp-runtime container image.
docker inspect cp.icr.io/cp/ai/watson-nlp-runtime:1.0.20
For example we can see, how it was build. We notice that container image was build with buildah to ensure that the container image is OCI compliant and able to run on various container runtimes and it based on an Universal Base Image.
"io.buildah.version": "1.26.2",
"io.k8s.description": "The Universal Base Image Minimal ... ",
We also see the environment specification the location of the models we are going to use.
"Env": [
"PATH=/usr/local/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin",
"container=oci",
...
"LOCAL_MODELS_DIR=/app/models"
],
3. Execute the example locally
These are the steps you can follow along to run the example from the GitHub project Run Watson NLP for Embed on your local computer with Docker .
Step 1: Clone the example project to your local computer
git clone https://github.com/thomassuedbroecker/watson-nlp-example-local-docker
cd watson-nlp-example-local-docker/code
Step 2: Set your IBM_ENTITLEMENT_KEY in the .env file
cat .env_template > .env
Edit the .env file.
# used as 'environment' variables
IBMCLOUD_ENTITLEMENT_KEY="YOUR_KEY"
Step 3: Execute the run-watson-nlp-with-docker.sh bash script
sh run-watson-nlp-with-docker.sh
- Example output:
# ******
# List model array content
# ******
Model 0 : watson-nlp_syntax_izumo_lang_en_stock:1.0.7
Model 1 : watson-nlp_syntax_izumo_lang_fr_stock:1.0.7
# ******
# If TLS credentials are set up, run with TLS
# ******
TLS is not configured
# ******
# Connect to IBM Cloud Container Image Registry: cp.icr.io/cp/ai
# ******
IBM_ENTITLEMENT_KEY: eyJ0eXAiOiJKV1QiLCJhbGciOiXXXXX.XXXXJJQk0gTWFya2V0cGxhY2UiLCJpYXQiOjE2NzEwOTc3MDQsImp0aSI6IjQzNDRhZmU4M2FhMDQwZTFiYTlmZDkwMzUyYzNmYWEzIn0.XXXXQZbEJGJ4BPR9XgXUcKkdNVTTQUJKHMU1m3mueU
flag needs an argument: --password
# ******
# Create volume for models
# ******
# 1. Clear out existing volume
model_data
# 2. Create a shared volume and initialize with open permissions
0741b26b357dc5a5fc0c002a6ed9da0cf2373c13e5a4f644b850cdc47bd9b3bc
# 3. Run a container in an interactive mode to set the permissions
# 4. Put models into the shared volume
Archive: /app/model.zip
inflating: config.yml
Load model model: watson-nlp_syntax_izumo_lang_en_stock:1.0.7 0
Archive: /app/model.zip
inflating: config.yml
Load model model: watson-nlp_syntax_izumo_lang_fr_stock:1.0.7 1
# ******
# Run NLP
# ******
# Run the runtime with the models mounted
[STARTING RUNTIME]
....
10001001I>", "message": "Common Service is running on port: 8085 with thread pool size: 5", "num_indent": 0, "thread_id": 140231246393600, "timestamp": "2022-12-15T17:18:13.453967"}
[STARTING GATEWAY]
2022/12/15 17:18:14 Running with INSECURE credentials
2022/12/15 17:18:14 Serving proxy calls INSECURE
Step 4: Verify the running Watson NLP container
Now we verify the running Watson NLP container by open a new terminal session and execute an API call.
- Available models
- syntax_izumo_lang_en_stock
- syntax_izumo_lang_fr_stock
- Example text
- This is a test sentence
- Ceci est une phrase test
curl -s \
"http://localhost:8080/v1/watson.runtime.nlp.v1/NlpService/SyntaxPredict" \
-H "accept: application/json" \
-H "content-type: application/json" \
-H "grpc-metadata-mm-model-id: syntax_izumo_lang_en_stock" \
-d '{ "raw_document": { "text": "This is a test sentence" }, "parsers": ["token"] }'
- Example output:
{"text":"This is a test sentence", "producerId":{"name":"Izumo Text Processing", "version":"0.0.1"}, "tokens":[{"span":{"begin":0, "end":4, "text":"This"}, "lemma":"", "partOfSpeech":"POS_UNSET", "dependency":null, "features":[]}, {"span":{"begin":5, "end":7, "text":"is"}, "lemma":"", "partOfSpeech":"POS_UNSET", "dependency":null, "features":[]}, {"span":{"begin":8, "end":9, "text":"a"}, "lemma":"", "partOfSpeech":"POS_UNSET", "dependency":null, "features":[]}, {"span":{"begin":10, "end":14, "text":"test"}, "lemma":"", "partOfSpeech":"POS_UNSET", "dependency":null, "features":[]}, {"span":{"begin":15, "end":23, "text":"sentence"}, "lemma":"", "partOfSpeech":"POS_UNSET", "dependency":null, "features":[]}], "sentences":[{"span":{"begin":0, "end":23, "text":"This is a test sentence"}}], "paragraphs":[{"span":{"begin":0, "end":23, "text":"This is a test sentence"}}]}
We executed the syntac predict endpoint. For more detail visit the API documentation v1/watson.runtime.nlp.v1/NlpService/SyntaxPredict REST API methode and the syntax_izumo_lang_en_stock model.
4. Summary
By taking a first basic look at the IBM Watson Natural Language Processing Library for Embed we can say that IBM Watson Libraries for Embed solutions are very flexible in configuration, because we can use them for various business use cases with pre-trained and custom models.The Libraries are very scalable, because to of their runtime is containerized and can run on different clouds and container runtimes.
I hope this was useful for you and let’s see what’s next?
Greetings,
Thomas
#ibmcloud, #watsonnlp, #ai, #bashscripting, #docker, #container, #ubi
