

The Cloud Native Starter project now contains the new great topic, the development of Reactive Microservices with Java, quarkus, MicroProfile and Vue.js as front-end. The Reactive example implementation runs on minikube, local OpenShift and on IBM Cloud Kubernetes. Here are the instructions on GitHub.
But what does reactive mean? Here is an extract of the definition in The Reactive Manifesto.
“Systems built as Reactive Systems are more flexible, loosely-coupled and scalable. This makes them easier to develop and amenable to change. They are significantly more tolerant of failure and when failure does occur they meet it with elegance rather than disaster. Reactive Systems are highly responsive, giving users effective interactive feedback.”
But be aware, our example is not a full Reactive System it shows reactive programming techniques.
Note: To understand the difference between these two topics, that badge on cognitiveclass is useful Reactive Architecture: Introduction to Reactive Systems.
In our reactive programming example, you see directly changes in the database on the Web UI, without refreshing the browser.
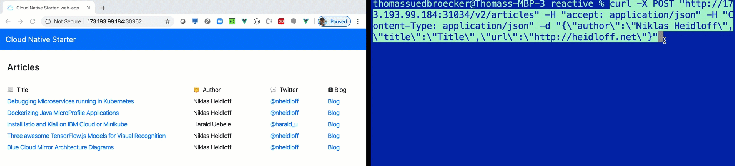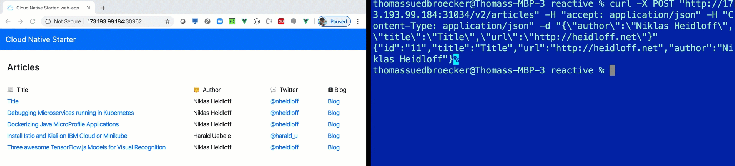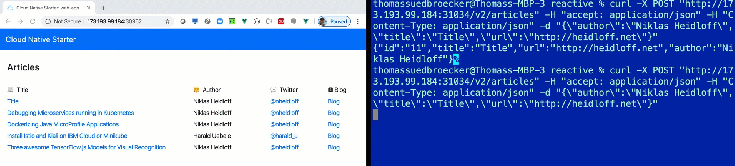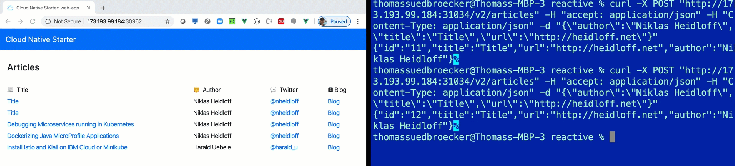
In this blog post I want to share, how you deploy that awesome Reactive example to a free IBM Cloud Kubernetes Cluster and using the free quota of the IBM Cloud Container Registry. We avoid for the setup that you have to use any paid IBM Cloud services, because you want just to see how the Reactive example works on IBM Cloud.
To create a free Cluster you need a feature code to create a Trial Account or you create a pay as you go account and you only use the free services of IBM Cloud.
That is the major architecture of the Reactive example. Three Java Microservices, one Vue UI application and two infrastructure components running on Kubernetes.

But what is reactive programming in more detail? If you want to get more details of the Reactive topic, just visit the blog post Development of Reactive Applications with Quarkus from Niklas Heidloff and if you want to explore the setup for local OpenShift take a look into the blog post Cloud Native Starter on Red Hat OpenShift 4 from Harald Uebele.
The concrete steps how to setup the Reactive example on a free IBM Cloud Kubernetes Cluster and how to use the Container Registry are here.
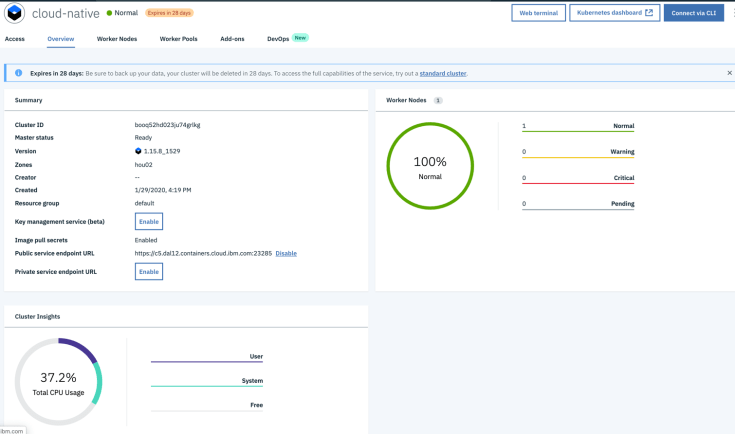
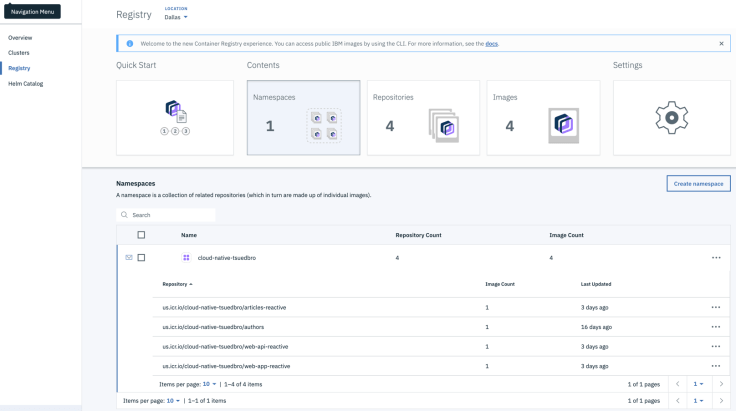
The two following images do show the Kubernetes Cluster and Container Registry on IBM Cloud.
| IBM Cloud Kubernetes Cluster | IBM Cloud Container Registry |
 |
 |
The following image provides a short overview of some steps, we did automate with bash scripts utilising the IBMCloud CLI and the kubectl CLI to deploy the needed Microservices to the IBM Cloud Kubernetes service.

The Reactive example
The Reactive example needs Kafka for the messaging and Postgres as the database to save the articles information. In the setup we install both open source components directly on the free Kubernetes Cluster on IBM Cloud.
To create an awesome user experience, we developed bash scripts to setup the example, that is similar to the other parts of the Cloud Native Starter project.
You see, you only need to execute seven scripts to setup the example on the IBM Cloud Kubernetes service, after you have created the cluster.
$ sh iks-scripts/deploy-kafka.sh $ sh iks-scripts/deploy-postgres.sh$ sh iks-scripts/deploy-articles-reactive-postgres.sh $ sh iks-scripts/deploy-authors.sh $ sh iks-scripts/deploy-web-api-reactive.sh $ sh iks-scripts/deploy-web-app-reactive.sh $ sh iks-scripts/show-urls.sh
Some details about the setup
Postgres database
IBM Cloud offers a paid Database for PostgreSQL service, but we haven’t use this option, because we want ensure you don’t need to spend any money to try out that Reactive example at IBM Cloud.
To deploy Postgres on a Kubernetes Cluster you need to use persistent storage volumes. The free Kubernetes Cluster on IBM Cloud has some restrictions, as you can see in the following image that contains a feature comparison for a free and a standard paid standard Kubernetes cluster. That means we can’t use persistent storage volumes in our setup. For more details just visit the link to the IBM Cloud documentation.
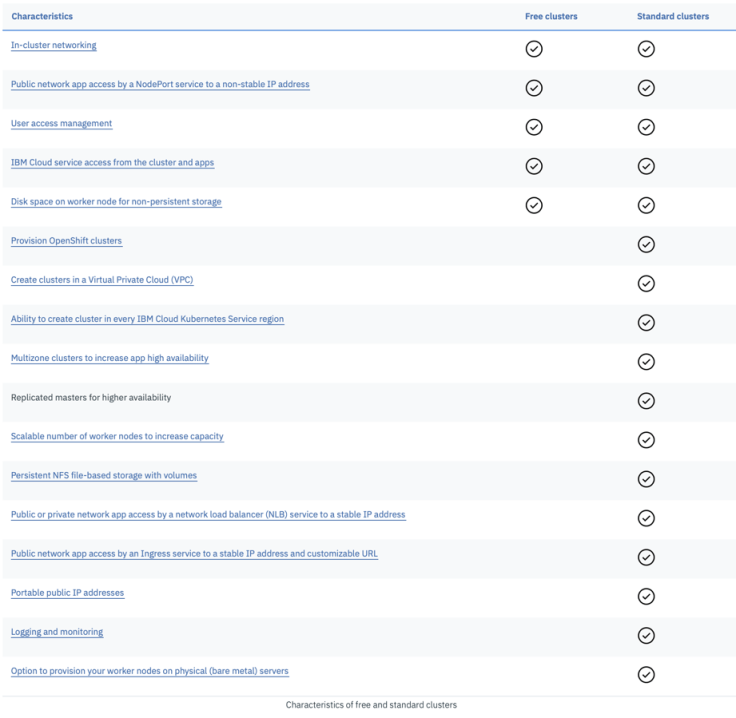
With this fact in mind, we deploy the Postgres as a Pod into a free Kubernetes instance. That means the data will be lost, when the Pod is restarted. The concrete postgres.yaml file configuration is here in our Cloud Native Starter project.
Kafka
To simplify the installation of Kafka in the free Cluster, we just replicate what we did in the minikube setup, where we used the Strimzi Kafka operator, but I want to highlight there is also a possibility to use a free Kafka service on IBM Cloud. Maybe we will integrate the free service in the future to the example.
If you want to dig more into details, visit the related blog posts to learn more about realization of that awesome Reactive example.
I hope this was useful for you and let’s see what’s next?
Greetings,
Thomas
PS: You can try out Cloud Foundry Apps or Kubernetes on IBM Cloud. By the way, you can use the IBM Cloud for free, if you simply create an IBM Lite account. Here you only need an e-mail address.
#IBMDeveloper, #IBMCloud, #Kubernetes, #Kafka, #Postgres, #MicroProfile, #Java
